SQL Relay Configuration Guide
- Quick Start
- Basic Configuration
- Modules
- Database Configuration
- Oracle
- Microsoft SQL Server (via ODBC)
- Microsoft SQL Server (via FreeTDS)
- SAP/Sybase (via the native SAP/Sybase library)
- SAP/Sybase (via FreeTDS)
- IBM DB2
- Informix
- MySQL/MariaDB
- PostgreSQL
- Firebird
- SQLite
- Teradata (via ODBC)
- Exasol (via ODBC)
- Apache Hive (via ODBC)
- Apache Impala (via ODBC)
- Amazon Redshift (via ODBC)
- Amazon Redshift (via PostgreSQL)
- Amazon Athena (via ODBC)
- Generic ODBC
- Database Connection Count
- Database Cursor Count
- Dynamic Scaling
- Listener Configuration
- Multiple Instances
- Starting Instances Automatically
- Client Protocol Options
- SQLRClient Protocol
- MySQL Protocol
- Basic Configuration
- Listener Options
- Authentication/Encryption Options
- Foreign Backend
- Special-Purpose Options
- Limitations
- PostgreSQL Protocol
- Multiple Protocols
- High Availability
- Load Balancing and Failover With Replicated Databases or Database Clusters
- Already-Load Balanced Databases
- Master-Slave Query Routing
- Front-End Load Balancing and Failover
- Security Features
- Front-End Encryption and Secure Authentication
- Back-End Encryption and Secure Authentication
- Run-As User and Group
- IP Filtering
- Password Files
- Password Encryption
- Connection Schedules
- Query Filtering
- Data Translation
- Query Parsing
- Query Translation
- Bind Variable Translation
- Result Set Header Translation
- Result Set Translation
- Result Set Row Translation
- Result Set Row Block Translation
- Error Translation
- Module Data
- Query Directives
- Query and Session Routing
- Custom Queries
- Triggers
- Logging
- Notifications
- Session-Queries
- Alternative Configuration File Options
- Advanced Configuration
Quick Start
In order to run, the SQL Relay server requires a configuration file. However, When SQL Relay is first installed, no such configuration file exists. You must create one in the appropriate location. This location depends on the platform and on how you installed SQL Relay.
- Unix and Linux
- Built from source - /usr/local/firstworks/etc/sqlrelay.conf (unless you specified a non-standard --prefix or --sysconfdir during the build)
- RPM package - /etc/sqlrelay.conf
- FreeBSD package - /usr/local/etc/sqlrelay.conf
- NetBSD package - /usr/pkg/etc/sqlrelay.conf
- OpenBSD package - /usr/local/etc/sqlrelay.conf
- Windows
- Built from source - C:\Program Files\Firstworks\etc\sqlrelay.conf
- Windows Installer package - C:\Program Files\Firstworks\etc\sqlrelay.conf (unless you specified a non-standard installation folder)
The most minimal sqlrelay.conf would be something like:
<?xml version="1.0"?>
<instances>
<instance id="example">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
This configuration defines an instance of SQL Relay named example that opens and maintains a pool of 5 persistent connections to the ora1 instance of an Oracle database using scott/tiger credentials.
The instance can be started using:
sqlr-start -id example
( NOTE: When installed from packages, SQL Relay may have to be started and stopped as root.)
and can be accessed from the local machine using:
sqlrsh -host localhost -user scott -password tiger
( NOTE: By default, the user and password used to access SQL Relay are the same as the user and password that SQL Relay is configured to use to access the database. That is, they are the values of the user and password parameters of the string attribute of the connection tag. )
By default, SQL Relay listens on all available network interfaces, and can be accessed remotely by hostname. For example, if the server running SQL Relay is named sqlrserver then it can be accessed from another system using:
sqlrsh -host sqlrserver -user scott -password tiger
The instance can be stopped using:
sqlr-stop -id example
All running instances of SQL Relay can be stopped using:
sqlr-stop
(without the -id argument)
Basic Configuration
The example above may be sufficient for many use cases, but SQL Relay has many configuration options. For a production deployment, you will alomst certainly want to configure it further.
Modules
The SQL Relay server is highly modular. Configuring it largely consists of telling it which modules to load, and which options to use for each module. There are database connection modules, protocol modules, authentication modules, modules related to security, data translation modules, logging and notification modules, and others.
The module that you'll most likely need to configure first is a database connection module.
Database Configuration
By default, SQL Relay assumes that it's connecting to an Oracle database, but database connection modules for many other databases are provided.
The dbase attribute of the instance tag specifies which database connection module to load.
The connect string options (options in the string attribute of the connection tag) specify which parameters to use when connecting to the database. Connect string options are different for each database.
The connections tag also supports a debug attribute. If debug="yes" is configured in the connections tag (not in an individual connection tag) then debugging information about the connection is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Examples, illustrating how to connect to specific databases, follow.
Oracle
In this example, SQL Relay is configured to connect to an Oracle database. The dbase attribute defaults to "oracle", so the dbase attribute may be omitted when connecting to an Oracle database. It is just set here for illustrative purposes.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="oracle">
<connections>
<connection string="user=scott;password=tiger;oracle_home=/u01/app/oracle/product/12.1.0;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
The oracle_home option refers to the base directory of an Oracle instance. On Windows platforms, it should be specified as a Windows-style path with doubled backslashes. For example:
C:\\Oracle\\ora12.1
The oracle_home option is often unnecessary though, as the ORACLE_HOME environment variable is usually set system-wide. Also, since Oracle 10g, the TNS_ADMIN environment variable is preferred to ORACLE_HOME, and the tns_admin option can be used to serve the same purpose. See the SQL Relay Configuration Reference for details on the tns_admin option.
The oracle_sid option refers to an entry in the tnsnames.ora file (usually $ORACLE_HOME/network/admin/tnsnames.ora or $TNS_ADMIN/tnsnames.ora) similar to:
ORCL =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = examplehost)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ora1)
)
)
( NOTE: The tnsnames.ora file must be readable by the user that the instance of SQL Relay runs as.)
If you are using Oracle Instant Client, then it's likely that you don't have an ORACLE_HOME/TNS_ADMIN, or a tnsnames.ora file. In that case, the oracle_sid can be set directly to a tnsnames-style expression and the oracle_home/tns_admin option can be omitted.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="oracle">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=(DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = examplehost)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ora1)))"/>
</connections>
</instance>
</instances>
See the SQL Relay Configuration Reference for other valid Oracle connect string options.
See Getting Started With Oracle for general assistance installing and configuring an Oracle database.
Microsoft SQL Server (via ODBC)
On Windows platforms, ODBC can be used to access a Microsoft SQL Server database. There is also a Microsoft-provided ODBC driver for some versions of Linux.
In this example, SQL Relay is configured to connect to a Microsoft SQL Server database via ODBC.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="odbc">
<connections>
<connection string="dsn=odbcdsn;user=odbcuser;password=odbcpassword"/>
</connections>
</instance>
</instances>
The dsn option in the string attribute of the connection tag refers to an ODBC DSN (Data Source Name).
On Windows platforms, the DSN is an entry in the Windows Registry, created by the ODBC Data Source Administrator (look for "Set up ODBC data sources" in the Control Panel or just run odbcad32.exe).
On Linux and Unix platforms, the DSN is an entry in the odbc.ini file (usually /etc/odbc.ini).
[exampledsn] Description=SQL Server Driver=ODBC Driver 11 for SQL Server Server=examplehost Port=1433 Database=
The Driver parameter refers to an entry in the odbcinst.ini file (usually /etc/odbcinst.ini) which identifies driver files:
[ODBC Driver 11 for SQL Server] Description=Microsoft ODBC Driver 11 for SQL Server Driver=/opt/microsoft/msodbcsql/lib64/libmsodbcsql-11.0.so.2270.0 Threading=1 UsageCount=1
( NOTE: The odbc.ini and odbcinst.ini files must be readable by the user that the instance of SQL Relay runs as.)
See the SQL Relay Configuration Reference for other valid ODBC connect string options.
See Getting Started With ODBC (on a non-MS platform) for general assistance installing and configuring ODBC on a non-MS platform.
Microsoft SQL Server (via FreeTDS)
On Windows platforms, ODBC can be used to access a Microsoft SQL Server database. There is also a Microsoft-provided ODBC driver for some versions of Linux.
However, on Linux and Unix platforms, access to Microsoft SQL Server databases is also available via FreeTDS.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="freetds">
<connections>
<connection string="server=FREETDSSERVER;user=freetdsuser;password=freetdspassword;db=freetdsdb"/>
</connections>
</instance>
</instances>
The server option refers to an entry in the freetds.conf file (usually /etc/freetds.conf or /usr/local/etc/freetds.conf) which identifies the database server, similar to:
[FREETDSSERVER] host = examplehost port = 1433 tds version = 7.0 client charset = UTF-8
( NOTE: The freetds.conf file must be readable by the user that the instance of SQL Relay runs as.)
See the SQL Relay Configuration Reference for other valid FreeTDS connect string options.
SAP/Sybase (via the native SAP/Sybase library)
In this example, SQL Relay is configured to connect to a SAP/Sybase database via the native SAP/Sybase library.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="sap">
<connections>
<connection string="sybase=/opt/sap;lang=en_US;server=SAPSERVER;user=sapuser;password=sappassword;db=sapdb"/>
</connections>
</instance>
</instances>
The sybase option refers to the base directory of the SAP/Sybase software installation. On Windows platforms, it should be specified as a Windows-style path with doubled backslashes. For example:
C:\\SAP
The sybase option is often unnecessary though, as the SYBASE environment variable is usually set system-wide.
On Linux/Unix platforms, the server option refers to an entry in the interfaces (usually $SYBASE/interfaces) file which identifies the database server, similar to:
SAPSERVER master tcp ether examplehost 5000 query tcp ether examplehost 5000
( NOTE: The interfaces file must be readable by the user that the instance of SQL Relay runs as.)
On Windows platforms, the server option refers to a similar entry created in an opaque location with the Open Client Directory Services Editor (dsedit).
The lang option sets the language to a value that is known to be supported by Sybase. This may not be necessary on all platforms. See the FAQ for more info.
See the SQL Relay Configuration Reference for other valid SAP/Sybase connect string options.
See Getting Started With SAP/Sybase for general assistance installing and configuring an SAP/Sybase database.
SAP/Sybase (via FreeTDS)
The native SAP/Sybase library is available on Windows and on some Linux/Unix platforms.
However, on Linux and Unix platforms, access to SAP/Sybase databases is also available via FreeTDS.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="freetds">
<connections>
<connection string="server=FREETDSSERVER;user=freetdsuser;password=freetdspassword;db=freetdsdb"/>
</connections>
</instance>
</instances>
The server option refers to an entry in the freetds.conf file (usually /etc/freetds.conf or /usr/local/etc/freetds.conf) which identifies the database server, similar to:
[FREETDSSERVER] host = examplehost port = 5000 tds version = 5.0
( NOTE: The freetds.conf file must be readable by the user that the instance of SQL Relay runs as.)
See the SQL Relay Configuration Reference for other valid FreeTDS connect string options.
See Getting Started With SAP/Sybase for general assistance installing and configuring an SAP/Sybase database.
IBM DB2
In this example, SQL Relay is configured to connect to an IBM DB2 database.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="db2">
<connections>
<connection string="db=exampledb;user=db2inst1;password=db2inst1pass;connecttimeout=0"/>
</connections>
</instance>
</instances>
The db option refers to an entry in the local DB2 instance's database catalog. See Getting Started With IBM DB2 - Accessing Remote Instances for more information.
The connecttimeout=0 option tells SQL Relay not to time out when connecting to the database. DB2 instances can take a long time to log in to sometimes. The default timeout is often too short.
See the SQL Relay Configuration Reference for other valid IBM DB2 connect string options.
See Getting Started With IBM DB2 for general assistance installing and configuring an IBM DB2 database.
Informix
In this example, SQL Relay is configured to connect to an Informix database.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="informix">
<connections>
<connection string="informixdir=/opt/informix;servername=ol_informix1210;db=informixdb;user=informixuser;password=informixpassword"/>
</connections>
</instance>
</instances>
The informixdir option refers to the base directory of the Informix software installation. On Windows platforms, it should be specified as a Windows-style pathwith doubled backslashes. For example:
C:\\Program Files\\IBM Informix Software Bundle
The informixdir option is often unnecessary, as the INFORMIXDIR environment variable is usually set system-wide.
On Linux and Unix platforms, the servername option refers to an entry in the sqlhosts file (usually $INFORMIXDIR/etc/sqlhosts) which identifies the database server, similar to:
ol_informix1210 onsoctcp 192.168.123.59 ol_informix1210
The second ol_informix1210 in the sqlhosts file refers to an entry in /etc/services which identifies the port that the server is listening on, similar to:
ol_informix1210 29756/tcp
( NOTE: The sqlhosts and /etc/services files must be readable by the user that the instance of SQL Relay runs as.)
On Windows platforms, the servername option refers to a similar entry created in an opaque location with the Setnet32 program.
See the SQL Relay Configuration Reference for other valid Informix connect string options.
MySQL/MariaDB
In this example, SQL Relay is configured to connect to a MySQL/MariaDB database.
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
The host and db options indicate that SQL Relay should connect to the database exampledb on the host examplehost.
See the SQL Relay Configuration Reference for other valid MySQL/MariaDB connect string options.
See Getting Started With MySQL for general assistance installing and configuring a MySQL/MariaDB database.
PostgreSQL
In this example, SQL Relay is configured to connect to a PostgreSQL database.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="postgresql">
<connections>
<connection string="user=postgresqluser;password=postgresqlpassword;host=postgresqlhost;db=postgresqldb"/>
</connections>
</instance>
</instances>
The host and db options indicate that SQL Relay should connect to the database exampledb on the host examplehost.
See the SQL Relay Configuration Reference for other valid PostgreSQL connect string options.
See Getting Started With PostgreSQL for general assistance installing and configuring a PostgreSQL database.
Firebird
In this example, SQL Relay is configured to connect to a Firebird database.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="firebird">
<connections>
<connection string="user=firebirduser;password=firebirdpassword;db=firebirdhost:/opt/firebird/firebirddb.gdb"/>
</connections>
</instance>
</instances>
The db option indicates that SQL Relay should connect to the database located at /opt/firebird/exampledb.gdb on the host examplehost.
Note that if the database is located on a Windows host, then the path segment of the db option should be specified as a Windows-style path with doubled backslashes. For example:
examplehost:C:\\Program Files\\Firebird\\Firebird_3_0\\exampledb.gdb
See the SQL Relay Configuration Reference for other valid Firebird connect string options.
See Getting Started With Firebird for general assistance installing and configuring a Firebird database.
SQLite
In this example, SQL Relay is configured to connect to a SQLite database.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="sqlite">
<connections>
<connection string="db=/var/sqlite/sqlitedb;user=sqliteuser;password=sqlitepassword"/>
</connections>
</instance>
</instances>
The db option indicates that SQL Relay should connect to the database /var/sqlite/exampledb.
Note that the database file (exampledb in this case) and the directory that its located in (/var/sqlite in this case) must both be readable and writable by the user that the instance of SQL Relay runs as.
Also note the user and password parameters in the connection string. SQLite doesn't require these for SQL Relay to access the database, but they are included to define a user and password for accessing SQL Relay itself.
SQLite also supports a high-performance in-memory mode where tables are maintained in memory and nothing is written to permanent storage. To use this mode with SQL Relay, set the db option to :memory:.
As each running instance of sqlr-connection will have its own separate in-memory database, you almost certainly want to limit the number of connections to 1.
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="sqlite" connections="1">
<connections>
<connection string="db=:memory:;user=sqliteuser;password=sqlitepassword"/>
</connections>
</instance>
</instances>
Note that the entire in-memory database will be lost when SQL Relay is stopped. There is no way to preserve it. Such is the nature of pure in-memory databases.
See the SQL Relay Configuration Reference for other valid SQLite connect string options.
See Getting Started With SQLite for general assistance installing and configuring a SQLite database.
Teradata (via ODBC)
Teradata ODBC drivers are available for many platforms, including Windows and Linux.
In this example, SQL Relay is configured to connect to a Teradata database via ODBC.
<?xml version="1.0"?> <instances> <instance id="example" dbase="odbc"> <connections> <connection string="dsn=teradata;user=teradatauser;password=teradatapassword"/> </connections> </instance> <instances>
The dsn option in the string attribute of the connection tag refers to an ODBC DSN (Data Source Name).
On Windows platforms, the DSN is an entry in the Windows Registry, created by the ODBC Data Source Administrator (look for "Set up ODBC data sources" in the Control Panel or just run odbcad32.exe).
On Linux and Unix platforms, the DSN is an entry in the odbc.ini file (usually /etc/odbc.ini).
[teradata] Description=Teradata Database ODBC Driver 16.20 Driver=/opt/teradata/client/16.20/lib64/tdataodbc_sb64.so DBCName=teradatahost UID=testuser PWD=testpassword AccountString= CharacterSet=ASCII DatasourceDNSEntries= DateTimeFormat=IAA DefaultDatabase= DontUseHelpDatabase=0 DontUseTitles=1 EnableExtendedStmtInfo=1 EnableReadAhead=1 IgnoreODBCSearchPattern=0 LogErrorEvents=0 LoginTimeout=20 MaxRespSize=65536 MaxSingleLOBBytes=0 MaxTotalLOBBytesPerRow=0 MechanismName= NoScan=0 PrintOption=N retryOnEINTR=1 ReturnGeneratedKeys=N SessionMode=System Default SplOption=Y TABLEQUALIFIER=0 TCPNoDelay=1 TdmstPortNumber=1025 UPTMode=Not set USE2XAPPCUSTOMCATALOGMODE=0 UseDataEncryption=0 UseDateDataForTimeStampParams=0
( NOTE: The odbc.ini file must be readable by the user that the instance of SQL Relay runs as.)
See the SQL Relay Configuration Reference for other valid ODBC connect string options.
Exasol (via ODBC)
Exasol ODBC drivers are available for Windows and Linux.
In this example, SQL Relay is configured to connect to an Exasol database via ODBC.
<?xml version="1.0"?> <instances> <instance id="example" dbase="odbc"> <connections> <connection string="dsn=exasolution-uo2214lv2_64;user=sys;password=exasol"/> </connections> </instance> <instances>
The dsn option in the string attribute of the connection tag refers to an ODBC DSN (Data Source Name).
On Windows platforms, the DSN is an entry in the Windows Registry, created by the ODBC Data Source Administrator (look for "Set up ODBC data sources" in the Control Panel or just run odbcad32.exe).
On Linux and Unix platforms, the DSN is an entry in the odbc.ini file (usually /etc/odbc.ini).
[exasolution-uo2214lv2_64] DRIVER=/home/dmuse/software/EXASOL_ODBC-6.0.11/lib/linux/x86_64/libexaodbc-uo2214lv2.so EXAHOST=192.168.123.12:8563 EXAUID=sys EXAPWD=exasol
( NOTE: The odbc.ini file must be readable by the user that the instance of SQL Relay runs as.)
See the SQL Relay Configuration Reference for other valid ODBC connect string options.
Apache Hive (via ODBC)
Apache Hive is a data warehouse built on top of Apache Hadoop. Cloudera provides a Hive ODBC driver for Windows and Linux platforms which implements a SQL interface to Hive. This driver has some quirks.
The most significant quirk is that version 2.6.4.1004 (and probably other versions) for Linux ship with their own copy of libssl/libcrypto, version 1.1. These tend to conflict with the versions of libssl/libcrypto that SQL Relay itself is linked against, causing the driver to malfunction. The only known solution is to build a copy of Rudiments and SQL Relay from source, configuring rudiments with the --disable-ssl --disable-gss --disable-libcurl options, and use this copy to access Hive. Unfortunately, this has a side effect of disabling all SSL/TLS and Kerberos support in SQL Relay, as well as disabling the ability to load config files over https and ssh. Perhaps a future version of the Cloudera Hive ODBC driver for Linux will link against the system versions of libssl/libcrypto and eliminate this quirk.
In this example, SQL Relay is configured to connect to a Apache Hive data warehouse via ODBC.
<?xml version="1.0"?> <instances> <instance id="example" dbase="odbc"> <session> <start> <runquery> use hivedb </runquery> <runquery> select 1 </runquery> </start> </session> <connections> <connection string="dsn=hive;user=hiveuser;password=hivepassword;db=hivedb;overrideschema=hivedb"/> </connections> </instance> <instances>
The contents of the session tag work around another quirk. "hivedb" is specified in the db option of the string attribute of the connection tag, but this doesn't appear to be adequate to actually put you in that schema. Running the "use hivedb" query at the beginning of the session helps. But, it appears that the schema isn't actually selected until the first query is run. So, the "select 1" query immediately following the use query solves this.
The overrideschema option in the string attribute of the connection tag works around yet another quirk. The database tends to report the current schema as something other than "hivedb", but when running "show tables" or "describe" queries, the database wants "hivedb" to be passed in as the schema for the table names.
The dsn option in the string attribute of the connection tag refers to an ODBC DSN (Data Source Name).
On Windows platforms, the DSN is an entry in the Windows Registry, created by the ODBC Data Source Administrator (look for "Set up ODBC data sources" in the Control Panel or just run odbcad32.exe).
On Linux and Unix platforms, the DSN is an entry in the odbc.ini file (usually /etc/odbc.ini).
[hive] Driver=/opt/cloudera/hiveodbc/lib/64/libclouderahiveodbc64.so HiveServerType=2 Host=hiveserver Port=10000
( NOTE: The odbc.ini file must be readable by the user that the instance of SQL Relay runs as.)
See the SQL Relay Configuration Reference for other valid ODBC connect string options.
Apache Impala (via ODBC)
Apache Impala is a query engine for Apache Hadoop. Cloudera provides an Impala ODBC driver for Windows and Linux platforms. This driver has some quirks.
The most significant quirk is that version 2.5.20 (and probably other versions) for Linux ship linked against libsasl2.so.2. This library can be found on RedHat Enterprise 6 (or CentOS 6) but modern Linux systems have moved on to newer versions. To use the driver, it is necessary to get a copy of libsasl2.so.2.0.23 (or a similar version) from an old enough system, install it in an appropriate lib directory, and create libsasl2.so.2 as a symlink to it in that same directory.
In this example, SQL Relay is configured to connect to a Impala database via ODBC.
<?xml version="1.0"?> <instances> <instance id="example" dbase="odbc"> <session> <start> <runquery> use default </runquery> <runquery> select 1 </runquery> </start> </session> <connections> <connection string="dsn=impala;overrideschema=%;unicode=no"/> </connections> </instance> <instances>
The contents of the session tag work around a quirk. Normally the schema would be selected by setting the db option of the string attribute of the connection tag, but this doesn't work at all. Running the "use default" query at the beginning of the session helps. But, it appears that the schema isn't actually selected until the first query is run. So, the "select 1" query immediately following the use query solves this.
The overrideschema option in the string attribute of the connection tag works around yet another quirk. When running "show tables" or "describe" queries, the database needs "%" (the SQL wildcard) to be passed in as the schema for the table names.
The driver also doesn't support unicode, so the unicode=no option in the string attribute of the connection tag tells SQL Relay not to try.
Note that there are no user/password options in the string attribute of the connection tag. Impala supports several different authentication mechanisms, but by default, it allows unauthenticated access to the database (AuthMech=0). This can be configured in the DSN though, and if a user/password authentication mechansim is selected, then the standard user/password options can be included.
The dsn option in the string attribute of the connection tag refers to an ODBC DSN (Data Source Name).
On Windows platforms, the DSN is an entry in the Windows Registry, created by the ODBC Data Source Administrator (look for "Set up ODBC data sources" in the Control Panel or just run odbcad32.exe).
On Linux and Unix platforms, the DSN is an entry in the odbc.ini file (usually /etc/odbc.ini).
[impala] Description=Cloudera ODBC Driver for Impala (64-bit) DSN Driver=Cloudera ODBC Driver for Impala 64-bit HOST=impalaserver PORT=21050 Database=impaladb AuthMech=0 UID=default PWD= TSaslTransportBufSize=1000 RowsFetchedPerBlock=10000 SocketTimeout=0 StringColumnLength=32767 UseNativeQuery=0
The Driver parameter refers to an entry in the odbcinst.ini file (usually /etc/odbcinst.ini) which identifies driver files:
[Cloudera ODBC Driver for Impala 64-bit] Description=Cloudera ODBC Driver for Impala (64-bit) Driver=/opt/cloudera/impalaodbc/lib/64/libclouderaimpalaodbc64.so
( NOTE: The odbc.ini and odbcinst.ini files must be readable by the user that the instance of SQL Relay runs as.)
See the SQL Relay Configuration Reference for other valid ODBC connect string options.
Amazon Redshift (via ODBC)
Amazon Redshift is a cloud-hosted data warehouse service. Amazon provides a Redshift ODBC driver for Windows and Linux platforms. This driver (or perhaps Redshift itself) has some quirks.
In this example, SQL Relay is configured to connect to a Redshift database via ODBC.
<?xml version="1.0"?> <instances> <instance id="example" dbase="odbc" ignoreselectdatabase="yes"> <connections> <connection string="dsn=redshift;user=redshiftuser;password=redshiftpassword;overrideschema=public"/> </connections> </instance> <instances>
The ignoreselectdatabase="yes" attribute of the instance tag works around a quirk. It instructs SQL Relay to ignore "use database" queries, or other attempts to select the current database/schema. These options tend to put the connection outside of any database/schema, and unable to return to the desired database/schema.
The overrideschema option in the string attribute of the connection tag works around another quirk. When running "show tables" or "describe" queries, the database needs "public" to be passed in as the schema for the table names.
The dsn option in the string attribute of the connection tag refers to an ODBC DSN (Data Source Name).
On Windows platforms, the DSN is an entry in the Windows Registry, created by the ODBC Data Source Administrator (look for "Set up ODBC data sources" in the Control Panel or just run odbcad32.exe).
On Linux and Unix platforms, the DSN is an entry in the odbc.ini file (usually /etc/odbc.ini).
[redshift] Driver=Amazon Redshift (x64) Host=redshifthost Database=redshiftdb Username=redshiftuser Password=redshiftpassword
The Driver parameter refers to an entry in the odbcinst.ini file (usually /etc/odbcinst.ini) which identifies driver files:
[Amazon Redshift (x64)] Description=Amazon Redshift ODBC Driver (64-bit) Driver=/opt/amazon/redshiftodbc/lib/64/libamazonredshiftodbc64.so
( NOTE: The odbc.ini and odbcinst.ini files must be readable by the user that the instance of SQL Relay runs as.)
See the SQL Relay Configuration Reference for other valid ODBC connect string options.
Amazon Redshift (via PostgreSQL)
Amazon Redshift is a cloud-hosted data warehouse service. Since it is based on PostgreSQL 8, it is possible to connect to a Redshift instance using the PostgreSQL client library.
<?xml version="1.0"?> <instances> <instance id="example" dbase="postgresql" ignoreselectdatabase="yes"> <connections> <connection string="host=redshifthost;port=5439;user=redshiftuser;password=redshiftpassword;db=redshiftdb;typemangling=lookup;tablemangling=lookup"/> </connections> </instance> <instances>
The ignoreselectdatabase="yes" attribute of the instance tag works around a quirk. It instructs SQL Relay to ignore "use database" queries, or other attempts to select the current database/schema. These options tend to put the connection outside of any database/schema, and unable to return to the desired database/schema.
The port option in the string attribute of the connection tag instructs SQL Relay to connect to the Redshift default port of 5439 rather than the PostgreSQL default port of 5432.
The typemangling and tablemangling options in the string attribute of the connection tag instruct SQL Relay to return data type and table names rather than data type and table object ID's (the default for PostgreSQL)
See the SQL Relay Configuration Reference for other valid PostgreSQL connect string options.
Amazon Athena (via ODBC)
Amazon Athena is an SQL interface to data stored in Amazon S3. Simba provides an Athena ODBC driver for Windows and Linux platforms. This driver (or perhaps Athena itself) has some quirks.
In this example, SQL Relay is configured to connect to a Athena database via ODBC.
<?xml version="1.0"?> <instances> <instance id="example" dbase="odbc"> <connections> <connection string="dsn=athena;user=RDXDE23X56D9822FFGE3;password=uEEmF+RDexoXpqTD5MiP3421emYP2M+4Rqo6GHio;overrideschema=athenadb"/> </connections> </instance> <instances>
Note the odd user and password options in the string attribute of the connection tag.
Note also that the db option is missing from the string attribute of the connection tag. The schema must be set in the DSN, and setting it in the connection string doesn't override the one set in the DSN.
The overrideschema option in the string attribute of the connection tag works around a quirk. The database tends to report the current schema as something other than "athenadb", but when running "show tables" or "describe" queries, the database wants "athenadb" to be passed in as the schema for the table names.
The dsn option in the string attribute of the connection tag refers to an ODBC DSN (Data Source Name).
On Windows platforms, the DSN is an entry in the Windows Registry, created by the ODBC Data Source Administrator (look for "Set up ODBC data sources" in the Control Panel or just run odbcad32.exe).
On Linux and Unix platforms, the DSN is an entry in the odbc.ini file (usually /etc/odbc.ini).
[athena] Description=Simba Athena ODBC Driver (64-bit) DSN Driver=/opt/simba/athenaodbc/lib/64/libathenaodbc_sb64.so AwsRegion=us-east-1 Schema=athenadb S3OutputLocation=s3://athenadata/ UID=RDXDE23X56D9822FFGE3 PWD=uEEmF+RDexoXpqTD5MiP3421emYP2M+4Rqo6GHio
The Driver parameter refers to an entry in the odbcinst.ini file (usually /etc/odbcinst.ini) which identifies driver files:
[Simba Athena ODBC Driver 64-bit] Description=Simba Athena ODBC Driver (64-bit) Driver=/opt/simba/athenaodbc/lib/64/libathenaodbc_sb64.so
( NOTE: The odbc.ini and odbcinst.ini files must be readable by the user that the instance of SQL Relay runs as.)
See the SQL Relay Configuration Reference for other valid ODBC connect string options.
Generic ODBC
ODBC can be used to access many databases for which SQL Relay has no native support.
Accessing a database via an ODBC driver usually involves:
- Installing the driver
- Creating a DSN
- On Windows this is done via a control panel
- On Linux/Unix it is done by adding entries to the odbc.ini and sometimes odbcinst.ini files
- Creating an instance of SQL Relay with dbase="odbc" which refers to the DSN, optionally specifying the user and password
See the examples above for more details. It should be possible to adapt one of them to the ODBC driver that you would like to use.
Note that many ODBC drivers have quirks. Many of the examples above demonstrate ways of working around some of these quirks.
Database Connection Count
By default, SQL Relay opens and maintains a pool of 5 persistent database connections, but the number of connections can be configured using the connections attribute.
<?xml version="1.0"?>
<instances>
<instance id="example" connections="10">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
The number of connections determines how many client applications can access the database simultaneously. In this example, up to 10, assuming each client only needs one connection. Additional clients would be queued and would have to wait for one of the first 10 to disconnect before being able to access the database.
( NOTE: Any number of connections may be configured, up to an "absolute max connections" limit defined at compile-time, which defaults to 4096. To find the limit on your system, run:
The command above also returns the "shmmax requirement" for the configuration. "shmmax" refers to the maximum size of a single shared memory segment, a tunable kernel parameter on most systems. The default shmmax requirement is about 5mb. On modern systems, shmmax defaults to at least 32mb, but on older systems it commonly defaulted to 512k. In any case, if the shmmax requirement exceeds the value of your system's shmmax parameter, then you will have to reconfigure the parameter before SQL Relay will start successfully. This may be done at runtime on most modern systems, but on older systems you may have to reconfigure and rebuild the kernel, and reboot.)sqlr-start -abs-max-connections
For Performance
In a performance-oriented configuration, a good rule of thumb is to open as many connections as you can. That number is usually environment-specific, and dictated by database, system and network resources.
For Throttling
If you intend to throttle database access to a particular application, then you may intentionally configure a small number of connections.
Database Cursor Count
Database cursors are used to execute queries and step through result sets. Most applications only need to use one cursor at a time. Some apps require more though, either because they run nested queries, or sometimes because they just don't properly free them.
SQL Relay maintains persistent cursors as well as connections. By default, each connection opens one cursor, but the number of cursors opened by each connection can be configured using the cursors attribute.
<?xml version="1.0"?>
<instances>
<instance id="example" connections="10" cursors="2">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
Any number of cursors can be opened. A good rule of thumb is to open as few as possible, but as many as you know that your application will need.
( NOTE: The documentation above says that by default, each connection opens one cursor, and this is true, but it would be more accurate to say that by default each connection opens one cursor, but will open additional cursors on-demand, up to 5. This is because it is common for an app to run at least one level of nested queries. For example, it is common to run a select and then run an insert, update, or delete for each row in the result set. Unfortunately, it is also not uncommon for apps to just manage cursors poorly. So, SQL Relay's default configuration offers a bit of flexibility to accommodate these circumstances. See the next section on Dynamic Scaling for more information about configuring connections and cursors to scale up and down on-demand.)
Dynamic Scaling
Both connections and cursors can be configured to scale dynamically - open on demand and then die off when no longer needed. This feature is useful if you have spikes in traffic during certain times of day or if your application has a few modules that occasionally need more cursors than usual.
The maxconnections and maxcursors attribute define the upper bounds.
<?xml version="1.0"?>
<instances>
<instance id="example" connections="10" maxconnections="20" cursors="2" maxcursors="10">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
In this example, 10 connections will be started initially but more will be be started on-demand, up to 20. Each of the newly spawned connections will die off if they are inactive for longer than 1 minute.
In this example, each connection will initially open 2 cursors but more will be opened on-demand, up to 10. Each newly opened cursor will be closed as soon as it is no longer needed.
Other attributes that control dynamic scaling behavior include:
- maxqueuelength
- growby
- ttl
- cursors_growby
See the SQL Relay Configuration Reference for more information on these attributes.
Listener Configuration
By default, SQL Relay listens for client connections on port 9000, on all available network interfaces.
It can be configured to listen on a different port though...
<?xml version="1.0"?>
<instances>
<instance id="example">
<listeners>
<listener protocol="sqlrclient" port="9001"/>
</listeners>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
...and accessed using:
sqlrsh -host sqlrserver -port 9001 -user scott -password tiger
It can also be configured to listen on a unix socket...
<?xml version="1.0"?>
<instances>
<instance id="example">
<listeners>
<listener protocol="sqlrclient" socket="/tmp/example.socket">
</listener>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
( NOTE: The user that SQL Relay runs as must be able to read and write to the path of the socket.)
...and accessed from the local server using:
sqlrsh -socket /tmp/example.socket -user scott -password tiger
If the server has multiple network interfaces, SQL Relay can also be configured to listen on specific IP addresses.
<?xml version="1.0"?>
<instances>
<instance id="example">
<listeners>
<listener protocol="sqlrclient" addresses="192.168.1.50,192.168.1.51"/>
</listeners>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
When configured this way, it can be accessed on 192.168.1.50 and 192.168.1.51 but not on 127.0.0.1 (localhost).
If the socket option is specified but port and addresses options are not, then SQL Relay will only listen on the socket. If addresses/port and socket options are both specified then it listens on both.
The listeners tag also supports a debug attribute. If debug="yes" is configured in the listeners tag (not in an individual listener tag) then debugging information about the listener is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Multiple Instances
Any number of SQL Relay instances can be defined in the configuration file.
In following example, instances that connect to Oracle, SAP/Sybase and DB2 are defined in the same file.
<?xml version="1.0"?>
<instances>
<instance id="oracleexample">
<listeners>
<listener port="9000"/>
</listeners>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
<instance id="sapexample" dbase="sap">
<listeners>
<listener port="9001"/>
</listeners>
<connections>
<connection string="sybase=/opt/sap;lang=en_US;server=SAPSERVER;user=sapuser;password=sappassword;db=sapdb"/>
</connections>
</instance>
<instance id="db2example" dbase="db2">
<listeners>
<listener port="9002"/>
</listeners>
<connections>
<connection string="db=db2db;user=db2inst1;password=db2inst1pass;lang=C;connecttimeout=0"/>
</connections>
</instance>
</instances>
These instances can be started using:
sqlr-start -id oracleexample sqlr-start -id sapexample sqlr-start -id db2example
( NOTE: When installed from packages, SQL Relay may have to be started and stopped as root.)
...and accessed using:
sqlrsh -host sqlrserver -port 9000 -user scott -password tiger sqlrsh -host sqlrserver -port 9001 -user sapuser -password sappassword sqlrsh -host sqlrserver -port 9002 -user db2inst1 -password db2inst1pass
Starting Instances Automatically
In all previous examples sqlr-start has been called with the -id option, specifying which instance to start. If sqlr-start is called without the -id option then it will start all instances configured with the enabled attribute set to yes.
For example, if the following instances are defined...
<?xml version="1.0"?>
<instances>
<instance id="oracleexample" enabled="yes">
<listeners>
<listener port="9000"/>
</listeners>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
<instance id="sapexample" enabled="yes" dbase="sap">
<listeners>
<listener port="9001"/>
</listeners>
<connections>
<connection string="sybase=/opt/sap;lang=en_US;server=SAPSERVER;user=sapuser;password=sappassword;db=sapdb"/>
</connections>
</instance>
<instance id="db2example" dbase="db2">
<listeners>
<listener port="9002"/>
</listeners>
<connections>
<connection string="db=db2db;user=db2inst1;password=db2inst1pass;lang=C;connecttimeout=0"/>
</connections>
</instance>
</instances>
...then calling sqlr-start without the -id parameter will start oracleexample and sapexample because enabled="yes" is configured for those instances. db2example will not be started because enabled="yes" is not configured for that instance.
When installed on most platforms, SQL Relay creates a systemd service file (usually in /usr/lib/systemd/system or /lib/systemd/system) or an init script in the appropriate place under /etc. These call sqlr-start with no -id option. If configured to run at boot, they will start all instances for which enabled="yes" is configured.
How to enable the service file or init script depends on what platform you are using.
On systemd-enabled Linux, this usually involves running:
systemctl enable sqlrelay.service
On non-systemd-enabled Linux, Solaris, SCO and other non-BSD Unixes, this usually involves creating a symlink from /etc/init.d/sqlrelay to /etc/rc3.d/S85sqlrelay. This can be done manually, but most platforms provide utilities to do it for you.
Redhat-derived Linux distributions have a chkconfig command that can do this for you:
chkconfig --add sqlrelay
Debian-derived Linux distributions provide the update-rc.d command:
update-rc.d sqlrelay defaults
Solaris provides svcadm:
svcadm enable sqlrelay
On FreeBSD you must add a line to /etc/rc.conf like:
sqlrelay_enabled=YES
On NetBSD you must add a line to /etc/rc.conf like:
sqlrelay=YES
On OpenBSD you must add a line to /etc/rc.conf like:
sqlrelay_flags=""
Client Protocol Options
Whether written using the native SQL Relay API, or a connector of some sort, SQL Relay apps generally communicate with SQL Relay using SQLRClient, the native SQL Relay client-server protocol.

However, SQL Relay also supports the MySQL and PostgreSQL client-server protocols. When SQL Relay is configured to use one of these, it allows MySQL/MariaDB and PostgreSQL apps to communicate directly with SQL Relay without modification, without having to install any software on the client.


In these configurations, SQL Relay becomes a transparent proxy. MySQL/MariaDB or PostgreSQL apps aimed at SQL Relay still think that they're talking to a MySQL/MariaDB or PostgreSQL database, but in fact, are talking to SQL Relay.
SQLRClient Protocol
SQLRClient is the native SQL Relay protocol, enabled by default. The example configurations above and throughout most of the rest of the guide configure SQL Relay to speak this protocol.
If an instance speaks the SQLRClient client-server protocol, then any client that wishes to use it must also speak the SQLRClient client-server protocol. This means that most software written using the SQL Relay native API, or written using a database abstraction layer which loads a driver for SQL Relay can access this instance. However, it also means that client programs for other databases (eg. the mysql, psql, and sqlplus command line programs, MySQL Workbench, Oracle SQL Developer, SQL Server Management Studio, etc.) cannot access this instance.
Basic Configuration
SQLRClient is the native SQL Relay protocol, no special tags or attributes are required to enable it.
<?xml version="1.0"?>
<instances>
<instance id="example">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
In this configuration:
- The connection tag instructs the instance to log in to the ora1 database as user scott with password tiger.
- By default, SQL Relay loads the sqlrclient protocol module, and listens on port 9000.
The instance can be started using:
sqlr-start -id example
and accessed from the local machine using:
sqlrsh -host localhost -user scott -password tiger
( NOTE: By default, the user and password used to access SQL Relay are the same as the user and password that SQL Relay is configured to use to access the database. That is, they are the values of the user and password parameters of the string attribute of the connection tag. )
By default, SQL Relay listens on all available network interfaces, on port 9000, and can be accessed remotely by hostname. For example, if the server running SQL Relay is named sqlrserver then it can be accessed from another system using:
sqlrsh -host sqlrserver -user scott -password tiger
The instance can be stopped using:
sqlr-stop -id example
Though it is not necessary, it is possible to explicitly configure SQL Relay to load the sqlrclient protocol module as follows:
<?xml version="1.0"?>
<instances>
<instance id="example">
<listeners>
<listener protocol="sqlrclient"/>
</listener>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
Since this instance speaks the SQLRClient client-server protocol, any client that wishes to use it must also speak the SQLRClient client-server protocol. This means that software written using the SQL Relay native API, or written using a database abstraction layer which loads a driver for SQL Relay can access this instance. However, it also means that client programs for other databases (eg. the mysql, psql, and sqlplus command line programs, MySQL Workbench, Oracle SQL Developer, SQL Server Management Studio, etc.) cannot access this instance.
Listener Options
By default, SQL Relay listens on port 9000.
However, it can be configured to listen on a different port.
<?xml version="1.0"?>
<instances>
<instance id="example">
<listeners>
<listener protocol="sqlrclient" port="9001"/>
</listeners>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
If the server has multiple network interfaces, SQL Relay can also be configured to listen on specific IP addresses.
<?xml version="1.0"?>
<instances>
<instance id="example">
<listeners>
<listener protocol="sqlrclient" addresses="192.168.1.50,192.168.1.51"/>
</listeners>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
In the example above, it can be accessed on 192.168.1.50 and 192.168.1.51 but not on 127.0.0.1 (localhost).
It can also be configured to listen on a unix socket by adding a socket attribute to the listener tag.
<?xml version="1.0"?>
<instances>
<instance id="example">
<listeners>
<listener protocol="sqlrclient" socket="/tmp/example.socket">
</listener>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
( NOTE: The user that SQL Relay runs as must be able to read and write to the path of the socket.)
If the socket option is specified but the port option is not, then SQL Relay will only listen on the socket. If port and socket options are both specified then it listens on both.
The SQLRClient protocol module also has a debug attribute. If debug="yes" is configured in the individual listener tag (not in the listeners tag), then debugging information about the protocol is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Authentication/Encryption Options
When using the SQLRClient protocol, there are several options for controlling which users are allowed to access an instance of SQL Relay.
Connect Strings Auth
The default authentication option is connect strings auth.
When connect strings authentication is used, a user is authenticated against the set of user/password combinations that SQL Relay is configured to use to access the database. That is, they are the values of the user and password parameters of the string attribute of the connection tag.
In the following example, SQL Relay is configured to access the database using scott/tiger credentials.
<?xml version="1.0"?>
<instances>
<instance id="example">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
In this case, clients would also use scott/tiger credentials to access SQL Relay.
Though it is not necessary, it is possible to explicitly configure SQL Relay to load the connect strings auth module as follows:
<?xml version="1.0"?>
<instances>
<instance id="example">
<auths>
<auth module="sqlrelay_connectstrings"/>
</auths>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
User List Auth
Another popular authentication option is user list auth.
When user list authentication is used, a user is authenticated against a static list of user/password combinations, which may be different than the user/password used that SQL Relay uses to access the database.
To enable user list auth, you must provide a list of user/password combinations, as follows:
<?xml version="1.0"?>
<instances>
<instance id="example">
<auths>
<auth module="sqlrclient_userlist">
<user user="oneuser" password="onepassword"/>
<user user="anotheruser" password="anotherpassword"/>
<user user="yetanotheruser" password="yetanotherpassword"/>
</auth>
</auths>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
Database Auth
Another popular authentication option is database auth.
The sqlrclient_database module can be used to authentication users directly against the database itself. This is useful when you want the credentials used to access SQL Relay to be the same as the credentials used to access the database, but it's inconvenient to maintain a duplicate list of users in the configuration file.
SQL Relay authenticates users against the database by checking the provided credentials against the credentials that are currently in use, and then, if they differ, logging out of the database and back in using the provided credentials.
To enable database auth, configure SQL Relay to load the sqlrclient_database auth module as follows.
<?xml version="1.0"?>
<instances>
<instance id="example">
<auths>
<auth module="sqlrclient_database"/>
</auths>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
( NOTE: Database authentication should not be used in an instance where dbase="router". It's OK for the instances that the router routes to to use it, but the router instance itself should not. If database authentication is used for that instance, then authentication will fail.)
In this configuration, SQL Relay initially logs in to the database as scott/tiger as specified in the connection tag. But each time a client connects, SQL Relay logs out and attempts to log back in as the user specified by the client, unless the user/password are the same as the current user.
For example, if a client initially connects using:
sqlrsh -host localhost -user scott -password tiger
...then SQL Relay doesn't need to log out and log back in.
But if the client then tries to connect using:
sqlrsh -host localhost -user anotheruser -password anotherpassword
..then SQL Relay does need to log out and log back in.
A subsequent connection using anotheruser/anotherpassword won't require a re-login, but a subsequent connection using any other user/password will.
Though this module is convenient, it has the disadvantage that logging in and out of the database over and over partially defeats SQL Relay's persistent connection pooling.
Proxied Auth
Another authentication option is proxied auth.
When proxied authentication is used, a user is authenticated against the database itself, though in a different manner than database authentication described above. SQL Relay logs into the database as a user with permissions to proxy other users. For each client session, SQL Relay checks the provided credentials against the credentials that are currently in use. If they differ, then it asks the proxy user to switch the user it's proxying to the provided user.
This is currently only supported with Oracle (version 8i or higher) and requires database configuration. See this document for more information including instructions for configuring Oracle.
To enable proxied auth, configure SQL Relay to load the proxied auth module as follows.
<?xml version="1.0"?>
<instances>
<instance id="example">
<auths>
<auth module="sqlrclient_proxied"/>
</auths>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
( NOTE: Proxied authentication should not be used in an instance where dbase="router". It's OK for the instances that the router routes to to use it, but the router instance itself should not. If proxied authentication is used for that instance, then authentication will fail.)
Kerberos and Active Directory Encryption and Authentication
SQL Relay supports Kerberos encryption and authentication between the SQL Relay client and SQL Relay Server.

When Kerberos encryption and authentication is used:
- All communications between the SQL Relay client and SQL Relay server are encrypted.
- A user who has authenticated against a Kerberos KDC or Active Directory Domain Controller can access SQL Relay without having to provide additional credentials.
On Linux and Unix systems, both server and client environments must be "Kerberized". On Windows systems, both server and client must join an Active Directory Domain. Note that this is only available on Professional or Server versions of Windows. Home versions cannot join Active Directory Domains.
The following configuration configures an instance of SQL Relay to use Kerberos authentication and encryption:
<?xml version="1.0"?> <instances> <instance id="example"> <listeners> <listener krb="yes" krbservice="sqlrelay" krbkeytab="/usr/local/firstworks/etc/sqlrelay.keytab"/> </listener> <auths> <auth module="sqlrclient_userlist"> <user user="dmuse@KRB.FIRSTWORKS.COM"/> <user user="kmuse@KRB.FIRSTWORKS.COM"/> <user user="imuse@KRB.FIRSTWORKS.COM"/> <user user="smuse@KRB.FIRSTWORKS.COM"/> <user user="FIRSTWORKS.COM\dmuse"/> <user user="FIRSTWORKS.COM\kmuse"/> <user user="FIRSTWORKS.COM\imuse"/> <user user="FIRSTWORKS.COM\smuse"/> </auth> </auths> <connections> <connection string="user=scott;password=tiger;oracle_sid=ora1"/> </connections> </instance> </instances>
- The krb attribute enables (or disables) Kerberos authentication and encryption.
- The krbservice attribute specifies which Kerberos service to use. This attribute is optional and defaults to "sqlrelay". It is only shown here for illustrative purposes.
- The krbkeytab attribute specifies the location of the keytab file containing the key for the specified Kerberos service. This attribute is not required on Windows. On Linux or Unix systems if this paramter is omitted, then it defaults to the system keytab, usually /etc/krb5.keytab
- User list authentication is also used. Other authentication methods are not currently supported with Kerberos.
Note that no passwords are required in the user list. Note also that users are specified in both user@REALM (Kerberos) format and REALM\user (Active Directory) format to support users authenticated against both systems.
To start the instance on a Linux or Unix system, you must be logged in as a user that can read the file specified by the krbkeytab attribute.
To start the instance on a Windows system, you must be logged in as a user that can proxy the service specified by the krbservice attribute (or it's default value of "sqlrelay" if omitted).
If those criteria are met, starting the Kerberized instance of SQL Relay is the same as starting any other instance:
sqlr-start -id example
( NOTE: When installed from packages, SQL Relay may have to be started and stopped as root.)
To access the instance, you must acquire a Kerberos ticket-granting ticket. On a Linux or Unix system, this typically involves running kinit, though a fully Kerberized environment may acquire this during login. On a Windows system, you must log in as an Active Directory domain user.
After acquiring the ticket-granting ticket, the instance of SQL Relay may be accessed from a Linux or Unix system as follows:
sqlrsh -host sqlrserver -krb
From a Windows system, it may be necessary to specify the fully qualified Kerberos service name as well:
sqlrsh -host sqlrserver -krb -krbservice sqlrelay/sqlrserver.firstworks.com@AD.FIRSTWORKS.COM
Note the absence of user and password parameters.
Kerberos authentication establishes trust between the user who acquired the ticket-granting ticket (the user running the client program) and the service (the SQL Relay server) as follows:
- The client program uses the user's ticket-granting ticket to acquire a ticket for the sqlrelay service.
- The client program then uses this service ticket to establish a security context with the SQL Relay server.
- During this process the client program sends the SQL Relay server the user name that was used to acquire the original ticket-granting ticket.
- If the security context can be successfully established, then the SQL Relay server can trust that the client program is being run by the user that it says it is.
Once the SQL Relay server trusts that the client is being run by the user that it says it is, the user is authenticated against the list of users.
While Kerberos authenticated and encrypted sessions are substantially more secure than standard SQL Relay sessions, several factors contribute to a performance penalty:
- The client program may have to acquire a service ticket from another server (the Kerberos KDC or Active Directory Domain Controller) prior to connecting to the SQL Relay server.
- When establishing the secure session, a significant amount of data must be sent back and forth between the client and server over multiple network round-trips.
- Kerberos imposes a limit on the amount of data that can be sent or received at once, so more round trips may be required when processing queries.
- Without dedicated encryption hardware and a Kerberos implementation that supports it, the computation involved in encrypting and decrypting data can also introduce delays.
Any kind of full session encryption should be used with caution in performance-sensitive applications.
TLS/SSL Encryption and Authentication
SQL Relay supports TLS/SSL encryption and authentication between the SQL Relay client and SQL Relay Server.

When TLS/SSL encryption and authentication is used:
- All communications between the SQL Relay client and SQL Relay server are encrypted.
- SQL Relay clients and servers may optionally validate each other's certificates and identities.
When using TLS/SSL encryption and authentication, at minimum, the SQL Relay server must be configured to load a certificate. For highly secure production environments, this certificate should come from a trusted certificate authority. In other environments the certificate may be self-signed, or even be borrowed from another server.
Encryption Only
The following configuration enables TLS/SSL encryption for an instance of SQL Relay:
<?xml version="1.0"?> <instances> <instance id="example"> <listeners> <listener tls="yes" tlscert="/usr/local/firstworks/etc/sqlrserver.pem"/> </listeners> <connections> <connection string="user=scott;password=tiger;oracle_sid=ora1"/> </connections> </instance> </instances>
- The tls attribute enables (or disables) TLS/SSL encryption.
- The tlscert attribute specifies the TLS/SSL certificate chain to use.
- (a .pem file is specified in this example, but on Windows systems, a .pfx file or Windows Certificate Store reference must be used. See The tlscert Parameter for details.)
- User list authentication is also used. Other authentication methods are not currently supported with TLS/SSL.
To start the instance on a Linux or Unix system, you must be logged in as a user that can read the file specified by the tlscert attribute. If that criterium is met then the instance can be started using:
sqlr-start -id example
( NOTE: When installed from packages, SQL Relay may have to be started and stopped as root.)
The instance may be accessed as follows:
sqlrsh -host sqlrserver -user scott -password tiger -tls -tlsvalidate no
This establishes a TLS/SSL-encrypted session but does not validate the server's certificate or identity. The session will only continue if the server's certificate is is well-formed and hasn't expired, but the client is still vulnerable to various attacks.
Certificate Validation
For a more secure session, the client may validate that the server's certificate was signed by a trusted certificate authority, known to the system, as follows:
sqlrsh -host sqlrserver -user scott -password tiger -tls -tlsvalidate ca
If the server's certificate is self-signed, then the certificate authority won't be known to the system, but it's certificate may be specified by the tlsca parameter as follows:
sqlrsh -host sqlrserver -user scott -password tiger -tls -tlsvalidate ca -tlsca /usr/local/firstworks/etc/myca.pem
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlsca Parameter for details.)
This establishes a TLS/SSL-encrypted session with the server and validates the server's certificate, but does not validate the server's identity. The session will only continue if the server's certificate is valid, but the client is still vulnerable to various attacks.
Host Name Validation
For a more secure session, the client may validate that the host name provided by the server's certificate matches the host name that the client meant to connect to, as follows:
sqlrsh -host sqlrserver.firstworks.com -user scott -password tiger -tls -tlsvalidate ca+host -tlsca /usr/local/firstworks/etc/myca.pem
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlsca Parameter for details.)
Note that the fully qualified host name was provided. Note also the use of the ca+host value for the tlsvalidate parameter. With these parameters, in addition to validating that the server's certificate was signed by a trusted certificate authority, the host name will also be validated. If the certificate contains Subject Alternative Names, then the host name will be compared to each of them. If no Subject Alternative Names are provided then the host name will be compared to the certificate's Common Name. The session will only continue if the sever's certificate and identity are both valid.
Domain Name Validation
Unless self-signed, certificates can be expensive, so certificates are often shared by multiple servers across a domain. To manage environments like this, the host name validation can be relaxed as follows, to just domain name validation:
sqlrsh -host sqlrserver.firstworks.com -user scott -password tiger -tls -tlsvalidate ca+domain -tlsca /usr/local/firstworks/etc/myca.pem
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlsca Parameter for details.)
Note that the fully qualified host name was provided. Note also the use of the ca+domain value for the tlsvalidate parameter. With these parameters, in addition to validating that the server's certificate was signed by a trusted certificate authority, the domain name portion of the host name will also be validated. If the certificate contains Subject Alternative Names, then the domain name portion of the host name will be compared to the domain name portion of each of them. If no Subject Alternative Names are provided then the domain name portion of the host name will be compared to the domain name portion of the certificate's Common Name. The session will only continue if the sever's certificate and domain identity are both valid.
Mutual Authentication
For an even more secure session, the server may also request a certificate from the client, validate the certificate, and optionally authenticate the client based on the host name provided by the certificate.
The following configuration enables these checks for an instance of SQL Relay:
<?xml version="1.0"?> <instances> <instance id="example"> <listeners> <listener tls="yes" tlscert="/usr/local/firstworks/etc/sqlrserver.pem" tlsvalidate="yes" tlsca="/usr/local/firstworks/etc/myca.pem"/> </listeners> <auths> <auth module="sqlrclient_userlist"> <user user="sqlrclient1.firstworks.com"/> <user user="sqlrclient2.firstworks.com"/> <user user="sqlrclient3.firstworks.com"/> <user user="sqlrclient4.firstworks.com"/> </auth> </auths> <connections> <connection string="user=scott;password=tiger;oracle_sid=ora1"/> </connections> </instance> </instances>
- The tlsvalidate attribute enables (or disables) validation that client's certificate was signed by a trusted certificate authority, known to the system, or as provided by the tlsca attribute.
- The tlsca attribute specifies a certificate authority to include when validating the client's certificate. This is useful when validating self-signed certificates.
- (a .pem file is specified in this example, but on Windows systems, a .pfx file or Windows Certificate Store reference must be used. See The tlsca Parameter for details.)
- User list authentication is also used.
Note that no passwords are required in the user list. In this configuration, the Subject Alternative Names in the client's certificate (or Common Name if no SAN's are present) are authenticate against the list of valid names.
Note also that when tlsvalidate is set to "yes", database and proxied authentication cannot currently be used. This is because database and proxied authentication both require a user name and password but the client certificate doesn't provide either.
To access the instance, the client must provide, at minimum, a certificate chain file (containing the client's certificate, private key, and signing certificates, as appropriate), as follows:
sqlrsh -host sqlrserver -tls -tlsvalidate no -tlscert /usr/local/firstworks/etc/sqlrclient.pem
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlscert Parameter for details.)
Note the absence of user and password parameters. Rather than passing a user and password, the client passes the specified certificate to the server. The server trusts that the client is who they say they are by virtue of having a valid certificate and the name provided by the certificate is authenticated against the list of valid names.
In a more likely use case though, mutual authentication occurs - the client validates the server's certificate and the server validates the client's certificate, as follows:
sqlrsh -host sqlrserver.firstworks.com -tls -tlscert /usr/local/firstworks/etc/sqlrclient.pem -tlsvalidate ca+host -tlsca /usr/local/firstworks/etc/myca.pem
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlscert Parameter and The tlsca Parameter for details.)
In this example, the client provides a certificate for the server to validate, validates the host's certificate against the provided certificate authority, and validates the host's identity against the provided host name.
Performance Considerations
While TLS/SSL authenticated and encrypted sessions are substantially more secure than standard SQL Relay sessions, several factors contribute to a performance penalty:
- When establishing the secure session, a significant amount of data must be sent back and forth between the client and server over multiple network round-trips.
- Some TLS/SSL implementations impose a limit on the amount of data that can be sent or received at once, so more round trips may be required when processing queries.
- Without dedicated encryption hardware and a TLS/SSL implementation that supports it, the computation involved in encrypting and decrypting data can also introduce delays.
Any kind of full session encryption should be used with caution in performance-sensitive applications.
MySQL Protocol
SQL Relay can be configured to speak the native MySQL protocol, enabling client programs for MySQL/MariaDB (eg. the mysql command line program and MySQL Workbench) to access SQL Relay directly.
If an instance speaks the MySQL client-server protocol, then any client that wishes to use it must also speak the MySQL client-server protocol. This means that most software written using the MySQL API, or written using a database abstraction layer which loads a driver for MySQL can access this instance. However, it also means that SQL Relay's standard sqlrsh client program and client programs for other databases (eg. the psql, and sqlplus command line programs, Oracle SQL Developer, SQL Server Management Studio, etc.) cannot access this instance.
Basic Configuration
To enable SQL Relay to speak the MySQL protocol, add the appropriate listener tag:
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3307"/> </listeners> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
In this configuration:
- The connection tag instructs the instance to log in to the mysqldb database on host mysqlhost as user mysqluser with password mysqlpassword.
- The listener tag instructs SQL Relay to load the mysql protocol module, and listen on port 3307.
The instance can be started using:
sqlr-start -id example
and accessed from the local machine using:
mysql --host=127.0.0.1 --port=3307 --user=sqlruser --password=sqlrpassword
( NOTE: 127.0.0.1 is used instead of "localhost" because "localhost" instructs the mysql client to use a predefined unix socket.)
( NOTE: By default, the user and password used to access SQL Relay are the same as the user and password that SQL Relay is configured to use to access the database. That is, they are the values of the user and password parameters of the string attribute of the connection tag. )
By default, SQL Relay listens on all available network interfaces, and can be accessed remotely by hostname. For example, if the server running SQL Relay is named sqlrserver then it can be accessed from another system using:
mysql --host=sqlrserver --port=3307 --user=sqlruser --password=sqlrpassword
The instance can be stopped using:
sqlr-stop -id example
Since this instance speaks the MySQL client-server protocol, any client that wishes to use it must also speak the MySQL client-server protocol. This means that most software written using the MySQL API, or written using a database abstraction layer which loads a driver for MySQL can access this instance. However, it also means that SQL Relay's standard sqlrsh client program and client programs for other databases (eg. the psql, and sqlplus command line programs, Oracle SQL Developer, SQL Server Management Studio, etc.) cannot access this instance.
Listener Options
In the example above, the instance is configured to listen on port 3307. The MySQL/MariaDB database typically listens on port 3306, so port 3307 was chosen to avoid collisions with the database itself.
However, if SQL Relay is run on a different server than the database, then it can be configured to run on port 3306. This is desirable when using SQL Relay as a transparent proxy.
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3306"/> </listeners> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
If the server has multiple network interfaces, SQL Relay can also be configured to listen on specific IP addresses.
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" addresses="192.168.1.50,192.168.1.51" port="3306"/> </listeners> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
In the example above, it can be accessed on 192.168.1.50 and 192.168.1.51 but not on 127.0.0.1 (localhost).
It can also be configured to listen on a unix socket by adding a socket attribute to the listener tag.
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3306" socket="/var/lib/mysql/mysql.sock"/> </listeners> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
( NOTE: The user that SQL Relay runs as must be able to read and write to the path of the socket.)
If the socket option is specified but the port option is not, then SQL Relay will only listen on the socket. If port and socket options are both specified then it listens on both.
The MySQL protocol module also has a debug attribute. If debug="yes" is configured in the individual listener tag (not in the listeners tag), then debugging information about the protocol is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Authentication/Encryption Options
When using the MySQL protocol, there are several options for controlling which users are allowed to access an instance of SQL Relay.
Connect Strings Auth
The default authentication option is connect strings auth.
When connect strings authentication is used, a user is authenticated against the set of user/password combinations that SQL Relay is configured to use to access the database. That is, they are the values of the user and password parameters of the string attribute of the connection tag.
In the following example, SQL Relay is configured to access the database using mysqlsuer/mysqlpassword credentials.
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3306"/> </listeners> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
In this case, clients would also use mysqluser/mysqlpassword credentials to access SQL Relay.
Though it is not necessary, it is possible to explicitly configure SQL Relay to load the connect strings auth module as follows:
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3306"/> </listeners> <auths> <auth module="mysql_connectstrings"/> </auths> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
User List Auth
Another popular authentication option is user list auth.
When user list authentication is used, a user is authenticated against a static list of user/password combinations, which may be different than the user/password used that SQL Relay uses to access the database.
To enable user list auth, you must provide a list of user/password combinations, as follows:
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3306"/> </listeners> <auths> <auth module="mysql_userlist"> <user user="oneuser" password="onepassword"/> <user user="anotheruser" password="anotherpassword"/> <user user="yetanotheruser" password="yetanotherpassword"/> </auth> </auths> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
When using SQL Relay as a transparent proxy, it is desirable to define the same set of users that are defined in the database itself. While this may sound inconvenient, in practice, most apps use a single user to access the database, and it's not uncommon for multiple apps to share a user. So, the list is typically short.
Database Auth
Another popular authentication option is database auth.
The mysql_database module can be used to authentication users directly against the database itself. This is useful when you want the credentials used to access SQL Relay to be the same as the credentials used to access the database, but it's inconvenient to maintain a duplicate list of users in the configuration file.
SQL Relay authenticates users against the database by checking the provided credentials against the credentials that are currently in use, and then, if they differ, logging out of the database and back in using the provided credentials.
To enable database auth, configure SQL Relay to load the mysql_database auth module as follows.
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3306"/> </listeners> <auths> <auth module="mysql_database"/> </auths> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
In this configuration, SQL Relay initially logs in to the database as mysqluser/mysqlpassword as specified in the connection tag. But each time a client connects, SQL Relay logs out and attempts to log back in as the user specified by the client, unless the user/password are the same as the current user.
For example, if a client initially connects using:
mysql --host=127.0.0.1 --user=mysqluser --password=mysqlpassword --default-auth=mysql_clear_password
...then SQL Relay doesn't need to log out and log back in.
But if the client then tries to connect using:
mysql --host=127.0.0.1 --user=anotheruser --password=anotherpassword --default-auth=mysql_clear_password
..then SQL Relay does need to log out and log back in.
A subsequent connection using anotheruser/anotherpassword won't require a re-login, but a subsequent connection using any other user/password will.
Though this module is convenient, it has two disadvantages.
- Logging in and out of the database over and over partially defeats SQL Relay's persistent connection pooling.
- The mysql_database module requires that the MySQL/MariaDB client send it an unencrypted password. In the examples above, the --default-auth=mysql_clear_password option is used to send an unencrypted password from the mysql command line program.
The second disadvantage may or may not be a problem, depending on how secure communications on your network need to be. Note that some MySQL and MariaDB distributions omit the necessary mysql_clear_password module. For example, the distributions available in the default CentOS 6 and 7 repositories omit the module. On these platforms, an alternative distribution of MySQL/MariaDB would have to be installed or built from source.
TLS/SSL Encryption and Authentication
SQL Relay supports TLS/SSL encryption and authentication between the MySQL/MariaDB client and SQL Relay Server.
When TLS/SSL encryption and authentication is used:
- All communications between the MySQL/MariaDB client and SQL Relay server are encrypted.
- MySQL/MariaDB clients and servers may optionally validate each other's certificates and identities.
When using TLS/SSL encryption and authentication, at minimum, the SQL Relay server must be configured to load a certificate. For highly secure production environments, this certificate should come from a trusted certificate authority. In other environments the certificate may be self-signed, or even be borrowed from another server.
Encryption Only
The following configuration enables TLS/SSL encryption for an instance of SQL Relay:
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3307" tls="yes" tlscert="/usr/local/firstworks/etc/sqlrserver.pem"/> </listeners> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
- The tls attribute enables (or disables) TLS/SSL encryption.
- The tlscert attribute specifies the TLS/SSL certificate chain to use.
- (a .pem file is specified in this example, but on Windows systems, a .pfx file or Windows Certificate Store reference must be used. See The tlscert Parameter for details.)
- User list authentication is also used. Other authentication methods are not currently supported with TLS/SSL.
To start the instance on a Linux or Unix system, you must be logged in as a user that can read the file specified by the tlscert attribute. If that criterium is met then the instance can be started using:
sqlr-start -id example
( NOTE: When installed from packages, SQL Relay may have to be started and stopped as root.)
The instance may be accessed as follows:
mysql --host=sqlrserver --user=sqlruser --password=sqlrpassword --ssl
(The "--ssl" option enables SSL/TLS encryption. As MySQL predates TLS, and originally used SSL, it's various SSL/TLS-related options all still begin with "--ssl".)
This establishes a TLS/SSL-encrypted session but does not validate the server's certificate or identity. The session will only continue if the server's certificate is is well-formed and hasn't expired, but the client is still vulnerable to various attacks.
Certificate Validation
For a more secure session, the client may validate that the server's certificate was signed by a trusted certificate authority, known to the system, as follows:
mysql --host=sqlrserver --user=sqlruser --password=sqlrpassword --ssl-verify-server-cert
(The --ssl option is not necessary in this invocation, as the --ssl-verify-server-cert option implies it.)
If the server's certificate is self-signed, then the certificate authority won't be known to the system, but it's certificate may be specified by the tlsca parameter as follows:
mysql --host=sqlrserver --user=sqlruser --password=sqlrpassword --ssl-verify-server-cert --ssl-ca=/usr/local/firstworks/etc/myca.pem
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlsca Parameter for details.)
This establishes a TLS/SSL-encrypted session with the server and validates the server's certificate, but does not validate the server's identity. The session will only continue if the server's certificate is valid, but the client is still vulnerable to various attacks.
Unfortunately, MySQL/MariaDB doesn't currently support host or domain name validation, so at present, the server's certificate can be validated, but the server's identity cannot.
Mutual Authentication
For an even more secure session, the server may also request a certificate from the client and validate the certificate.
The following configuration enables these checks for an instance of SQL Relay:
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3307" tls="yes" tlscert="/usr/local/firstworks/etc/sqlrserver.pem" tlsvalidate="yes" tlsca="/usr/local/firstworks/etc/myca.pem"/> </listeners> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
- The tlsvalidate attribute enables (or disables) validation that client's certificate was signed by a trusted certificate authority, known to the system, or as provided by the tlsca attribute.
- The tlsca attribute specifies a certificate authority to include when validating the client's certificate. This is useful when validating self-signed certificates.
- (a .pem file is specified in this example, but on Windows systems, a .pfx file or Windows Certificate Store reference must be used. See The tlsca Parameter for details.)
To access the instance, the client must provide, at minimum, a certificate chain file (containing the client's certificate, private key, and signing certificates, as appropriate), as follows:
mysql --host=sqlrserver --user=sqlruser --password=sqlrpassword --ssl-cert=/usr/local/firstworks/etc/sqlrclient.pem
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlscert Parameter for details.)
In a more likely use case though, mutual authentication occurs - the client validates the server's certificate and the server validates the client's certificate, as follows:
mysql --host=sqlrserver --user=sqlruser --password=sqlrpassword --ssl-cert=/usr/local/firstworks/etc/sqlrclient.pem --ssl-verify-server-cert --ssl-ca=/usr/local/firstworks/etc/myca.pem
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlscert Parameter and The tlsca Parameter for details.)
In this example, the client provides a certificate for the server to validate, validates the host's certificate against the provided certificate authority, and validates the host's identity against the provided host name.
SQL Relay can validate the client's certificate, and reject clients which present invalid certificates, but cannot yet authenticate the user via the Subject Alternative Name or Common Name presented in the certificate in lieu of a MySQL/MariaDB username. As such, a username and password must still be supplied for authentication in this configuration.
Performance Considerations
While TLS/SSL authenticated and encrypted sessions are substantially more secure than standard SQL Relay sessions, several factors contribute to a performance penalty:
- When establishing the secure session, a significant amount of data must be sent back and forth between the client and server over multiple network round-trips.
- Some TLS/SSL implementations impose a limit on the amount of data that can be sent or received at once, so more round trips may be required when processing queries.
- Without dedicated encryption hardware and a TLS/SSL implementation that supports it, the computation involved in encrypting and decrypting data can also introduce delays.
Any kind of full session encryption should be used with caution in performance-sensitive applications.
Foreign Backend
Since SQL Relay supports a variety of database back-ends, the app can also be redirected to any of these databases, instead of the MySQL/MariaDB database it was originally written to use.
This is as simple as specifying a different database using the dbase attribute in the instance tag and specifying the appropriate database connection string in the string attribute of the connection tag.
<?xml version="1.0"?> <instances> <instance id="example" dbase="oracle"> <listeners> <listener protocol="mysql" port="3306"/> </listeners> <connections> <connection string="user=scott;password=tiger;oracle_sid=ora1"/> </connections> </instance> </instances>
In this example, a MySQL front-end provides MySQL/MariaDB applications access to an Oracle back-end database.
Depending on the back-end, it might also be necessary to make some other configuration changes, as well, for example:
- In the instance tag:
- set translatebindvariables="yes"
- set the isolationlevel attribute
- In the string attribute of the connection tag:
- set autocommit=yes or autocommit=no
- set faketransactionblocks=yes
- implement a function that returns the last insert id and specify it using the lastinsertidfunction parameter
- set the identity parameter to override the database type
- set ignorespace=yes
- set the overrideschema parameter
- set the typemangling and/or tablemangling parameters
- use Query Translation modules
- use Result Set Translation modules
- use Error Translation modules
- use Session Queries
- use one of the Special-Purpose Options described below
In your app, it might stil be necessary to modify some queries to use the syntax of the foreign database, or even update some code, but a full rewrite of the app should not be necessary.
Special-Purpose Options
Mapping zero-scale DECIMAL to BIGINT
When targeting a foreign back-end...
Some back-end databases, like Oracle, don't have integer types. An integer type is really just a DECIMAL with a scale of 0.
By default, the MySQL protocol module maps zero-scale DECIMAL types to the MySQL DECIMAL type. Buy you might want to map them to the MySQL BIGINT type instead.
The zeroscaledecimaltobigint option instructs the module to do this mapping.
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3306" zeroscaledecimaltobigint="yes"/> </listeners> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
Mapping DATE to DATETIME
When targeting a foreign back-end...
Some back-end databases, like Oracle, don't have separate DATE and DATETIME types. Instead, they just have a DATE type, which can store date and time parts, and which parts are returned depend on a parameter like NLS_DATE_FORMAT.
By default, the MySQL protocol module maps the DATE type to the MySQL DATE type. But, if you are using DATE type fields to store date/times and have the database configured to return date and time parts, then you might want the DATE type mapped to the MySQL DATETIME type.
The datetodatetime option instructs the module to do this mapping.
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3306" datetodatetime="yes"/> </listeners> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
Supporting Older MariaDB JDBC Drivers
Older MariaDB JDBC drivers had a bug related to fetching the server's capability flags, and would reliably throw a NullPointerException when attempting to connect.
(I'm not sure exactly what versions this bug is present in. It's present in version 1.4.6, but fixed by 2.1.1.)
The oldmariadbjdbcservercapabilitieshack option instructs the module to return server capability flags that don't upset the old driver.
<?xml version="1.0"?> <instances> <instance id="example" dbase="mysql"> <listeners> <listener protocol="mysql" port="3306" oldmariadbjdbcservercapabilitieshack="yes"/> </listeners> <connections> <connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/> </connections> </instance> </instances>
Limitations
The implementation of the MySQL protocol is likely sufficient for most applications, but it isn't 100% complete. Some notable limitations follow:
- Only LATIN1_SWEDISH_CI and UTF8_GENERAL_CI character sets are supported.
- Only the mysql_native_password and mysql_clear_password authentication methods are supported. Notably, mysql_old_password and authentication_windows_client are not supported.
- Multi-statement queries are not supported.
- mysql_change_user() is not supported.
- mysql_send_long_data() is not supported.
- mysql_info() will always returns NULL when used with SQL Relay.
- MYSQL_FIELD.org_name/org_name_length and MYSQL_FIELD.org_table/org_table_length are not supported.
- Kerberos authentication and encryption are not supported.
PostgreSQL Protocol
SQL Relay can be configured to speak the native PostgreSQL protocol, enabling client programs for PostgreSQL (eg. the psql command line program) to access SQL Relay directly.
If an instance speaks the PostgreSQL client-server protocol, then any client that wishes to use it must also speak the PostgreSQL client-server protocol. This means that most software written using the PostgreSQL API, or written using a database abstraction layer which loads a driver for PostgreSQL can access this instance. However, it also means that SQL Relay's standard sqlrsh client program and client programs for other databases (eg. the psql, and sqlplus command line programs, MySQL Workbench, Oracle SQL Developer, SQL Server Management Studio, etc.) cannot access this instance.
Basic Configuration
To enable SQL Relay to speak the PostgreSQL protocol, add the appropriate listener tag:
<?xml version="1.0"?> <instances> <instance id="example" dbase="postgresql"> <listeners> <listener protocol="postgresql" port="5433"/> </listeners> <connections> <connection string="user=postgresqluser;password=postgresqlpassword;db=postgresqldb;host=postgresqlhost"/> </connections> </instance> </instances>
In this configuration:
- The connection tag instructs the instance to log in to the postgresqldb database on host postgresqlhost as user postgresqluser with password postgresqlpassword.
- The listener tag instructs SQL Relay to load the postgresql protocol module, and listen on port 5433.
The instance can be started using:
sqlr-start -id example
and accessed from the local machine using:
psql -h localhost -p 5433 -U sqlruser
( NOTE: By default, the user and password used to access SQL Relay are the same as the user and password that SQL Relay is configured to use to access the database. That is, they are the values of the user and password parameters of the string attribute of the connection tag. )
By default, SQL Relay listens on all available network interfaces, and can be accessed remotely by hostname. For example, if the server running SQL Relay is named sqlrserver then it can be accessed from another system using:
psql -h sqlrserver -p 5433 -U sqlruser
The instance can be stopped using:
sqlr-stop -id example
Since this instance speaks the PostgreSQL client-server protocol, any client that wishes to use it must also speak the PostgreSQL client-server protocol. This means that most software written using the PostgreSQL API, or written using a database abstraction layer which loads a driver for PostgreSQL can access this instance. However, it also means that SQL Relay's standard sqlrsh client program and client programs for other databases (eg. the mysql, and sqlplus command line programs, MySQL Workbench, Oracle SQL Developer, SQL Server Management Studio, etc.) cannot access this instance.
Listener Options
In the example above, the instance is configured to listen on port 5433. The MySQL/MariaDB database typically listens on port 5432, so port 5433 was chosen to avoid collisions with the database itself.
However, if SQL Relay is run on a different server than the database, then it can be configured to run on port 5432. This is desirable when using SQL Relay as a transparent proxy.
<?xml version="1.0"?> <instances> <instance id="example" dbase="postgresql"> <listeners> <listener protocol="postgresql" port="5432"/> </listeners> <connections> <connection string="user=postgresqluser;password=postgresqlpassword;db=postgresqldb;host=postgresqlhost"/> </connections> </instance> </instances>
If the server has multiple network interfaces, SQL Relay can also be configured to listen on specific IP addresses.
<?xml version="1.0"?> <instances> <instance id="example" dbase="postgresql"> <listeners> <listener protocol="postgresql" addresses="192.168.1.50,192.168.1.51" port="5432"/> </listeners> <connections> <connection string="user=postgresqluser;password=postgresqlpassword;db=postgresqldb;host=postgresqlhost"/> </connections> </instance> </instances>
In the example above, it can be accessed on 192.168.1.50 and 192.168.1.51 but not on 127.0.0.1 (localhost).
It can also be configured to listen on a unix socket by adding a socket attribute to the listener tag.
<?xml version="1.0"?> <instances> <instance id="example" dbase="postgresql"> <listeners> <listener protocol="postgresql" port="5432" socket="/tmp/.s.PGSQL.5432"/> </listeners> <connections> <connection string="user=postgresqluser;password=postgresqlpassword;db=postgresqldb;host=postgresqlhost"/> </connections> </instance> </instances>
( NOTE: The user that SQL Relay runs as must be able to read and write to the path of the socket.)
If the socket option is specified but the port option is not, then SQL Relay will only listen on the socket. If port and socket options are both specified then it listens on both.
The PostgreSQL protocol module also has a debug attribute. If debug="yes" is configured in the individual listener tag (not in the listeners tag), then debugging information about the protocol is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Authentication/Encryption Options
When using the PostgreSQL protocol, there are several options for controlling which users are allowed to access an instance of SQL Relay.
Connect Strings Auth
The default authentication option is connect strings auth.
When connect strings authentication is used, a user is authenticated against the set of user/password combinations that SQL Relay is configured to use to access the database. That is, they are the values of the user and password parameters of the string attribute of the connection tag.
In the following example, SQL Relay is configured to access the database using postgresqlsuer/postgresqlpassword credentials.
<?xml version="1.0"?> <instances> <instance id="example" dbase="postgresql"> <listeners> <listener protocol="postgresql" port="5432"/> </listeners> <connections> <connection string="user=postgresqluser;password=postgresqlpassword;db=postgresqldb;host=postgresqlhost"/> </connections> </instance> </instances>
In this case, clients would also use postgresqluser/postgresqlpassword credentials to access SQL Relay.
Though it is not necessary, it is possible to explicitly configure SQL Relay to load the connect strings auth module as follows:
<?xml version="1.0"?> <instances> <instance id="example" dbase="postgresql"> <listeners> <listener protocol="postgresql" port="5432"/> </listeners> <auths> <auth module="postgresql_connectstrings"/> </auths> <connections> <connection string="user=postgresqluser;password=postgresqlpassword;db=postgresqldb;host=postgresqlhost"/> </connections> </instance> </instances>
User List Auth
Another popular authentication option is user list auth.
When user list authentication is used, a user is authenticated against a static list of user/password combinations, which may be different than the user/password used that SQL Relay uses to access the database.
To enable user list auth, you must provide a list of user/password combinations, as follows:
<?xml version="1.0"?> <instances> <instance id="example" dbase="postgresql"> <listeners> <listener protocol="postgresql" port="5432"/> </listeners> <auths> <auth module="postgresql_userlist"> <user user="oneuser" password="onepassword"/> <user user="anotheruser" password="anotherpassword"/> <user user="yetanotheruser" password="yetanotherpassword"/> </auth> </auths> <connections> <connection string="user=postgresqluser;password=postgresqlpassword;db=postgresqldb;host=postgresqlhost"/> </connections> </instance> </instances>
When using SQL Relay as a transparent proxy, it is desirable to define the same set of users that are defined in the database itself. While this may sound inconvenient, in practice, most apps use a single user to access the database, and it's not uncommon for multiple apps to share a user. So, the list is typically short.
If the database has a lot of users, or users are added, deleted, or updated regularly, then it might be inconvenient to maintain a duplicate list of users in the configuration file. Unfortunately there isn't currently a postgresql_database auth module that can be used to auth users directly against the database, so for now this is the only option.
TLS/SSL Encryption and Authentication
SQL Relay supports TLS/SSL encryption and authentication between the PostgreSQL client and SQL Relay Server.
When TLS/SSL encryption and authentication is used:
- All communications between the PostgreSQL client and SQL Relay server are encrypted.
- PostgreSQL clients and servers may optionally validate each other's certificates and identities.
When using TLS/SSL encryption and authentication, at minimum, the SQL Relay server must be configured to load a certificate. For highly secure production environments, this certificate should come from a trusted certificate authority. In other environments the certificate may be self-signed, or even be borrowed from another server.
Encryption Only
The following configuration enables TLS/SSL encryption for an instance of SQL Relay:
<?xml version="1.0"?> <instances> <instance id="example" dbase="postgresql"> <listeners> <listener protocol="postgresql" port="5433" tls="yes" tlscert="/usr/local/firstworks/etc/sqlrserver.pem"/> </listeners> <connections> <connection string="user=postgresqluser;password=postgresqlpassword;db=postgresqldb;host=postgresqlhost"/> </connections> </instance> </instances>
- The tls attribute enables (or disables) TLS/SSL encryption.
- The tlscert attribute specifies the TLS/SSL certificate chain to use.
- (a .pem file is specified in this example, but on Windows systems, a .pfx file or Windows Certificate Store reference must be used. See The tlscert Parameter for details.)
- User list authentication is also used. Other authentication methods are not currently supported with TLS/SSL.
To start the instance on a Linux or Unix system, you must be logged in as a user that can read the file specified by the tlscert attribute. If that criterium is met then the instance can be started using:
sqlr-start -id example
( NOTE: When installed from packages, SQL Relay may have to be started and stopped as root.)
The instance may be accessed as follows:
PGSSLMODE=require psql -h sqlrserver -U sqlruser
This establishes a TLS/SSL-encrypted session but does not validate the server's certificate or identity. The session will only continue if the server's certificate is is well-formed and hasn't expired, but the client is still vulnerable to various attacks.
Certificate Validation
For a more secure session, the client may validate that the server's certificate was signed by a trusted certificate authority, known to the system, as follows:
PGSSLMODE=verify-ca psql -h sqlrserver -U sqlruser
If the server's certificate is self-signed, then the certificate authority won't be known to the system, but it's certificate may be specified by the tlsca parameter as follows:
PGSSLMODE=verify-ca PGSSLROOTCERT=/usr/local/firstworks/etc/myca.pem psql -h sqlrserver -U sqlruser
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlsca Parameter for details.)
This establishes a TLS/SSL-encrypted session with the server and validates the server's certificate, but does not validate the server's identity. The session will only continue if the server's certificate is valid, but the client is still vulnerable to various attacks.
Host Name Validation
For a more secure session, the client may validate that the host name provided by the server's certificate matches the host name that the client meant to connect to, as follows:
PGSSLMODE=verify-full PGSSLROOTCERT=/usr/local/firstworks/etc/myca.pem psql -h sqlrserver.firstworks.com -U sqlruser
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlsca Parameter for details.)
Note that the fully qualified host name was provided. Note also the use of the verify-full value for the PGSSLMODE environment variable. With these parameters, in addition to validating that the server's certificate was signed by a trusted certificate authority, the host name will also be validated. If the certificate contains Subject Alternative Names, then the host name will be compared to each of them. If no Subject Alternative Names are provided then the host name will be compared to the certificate's Common Name. The session will only continue if the sever's certificate and identity are both valid.
The PostgreSQL client only appears to support fully qualified host name validation. It does not appear possible to instruct the client to only validate the domain portion of the host name.
Mutual Authentication
For an even more secure session, the server may also request a certificate from the client, validate the certificate, and optionally authenticate the client based on the host name provided by the certificate.
The following configuration enables these checks for an instance of SQL Relay:
<?xml version="1.0"?> <instances> <instance id="example" dbase="postgresql"> <listeners> <listener protocol="postgresql" port="5433" tls="yes" tlscert="/usr/local/firstworks/etc/sqlrserver.pem" tlsvalidate="yes" tlsca="/usr/local/firstworks/etc/myca.pem"/> </listeners> <connections> <connection string="user=postgresqluser;password=postgresqlpassword;db=postgresqldb;host=postgresqlhost"/> </connections> </instance> </instances>
- The tlsvalidate attribute enables (or disables) validation that client's certificate was signed by a trusted certificate authority, known to the system, or as provided by the tlsca attribute.
- The tlsca attribute specifies a certificate authority to include when validating the client's certificate. This is useful when validating self-signed certificates.
- (a .pem file is specified in this example, but on Windows systems, a .pfx file or Windows Certificate Store reference must be used. See The tlsca Parameter for details.)
- User list authentication is also used.
Note that no passwords are required in the user list. In this configuration, the Subject Alternative Names in the client's certificate (or Common Name if no SAN's are present) are authenticated against the list of valid names.
Note also that when tlsvalidate is set to "yes", database and proxied authentication cannot currently be used. This is because database and proxied authentication both require a user name and password but the client certificate doesn't provide either.
To access the instance, the client must provide, at minimum, a certificate chain file (containing the client's certificate, private key, and signing certificates, as appropriate), as follows:
PGSSLMODE=verify-full PGSSLCERT=/usr/local/firstworks/etc/sqlrclient.pem PGSSLKEY=/usr/local/firstworks/etc/sqlrclient.pem psql -h sqlrserver.firstworks.com -U sqlruser
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlscert Parameter for details.)
Note that the PGSSLCERT and PGSSLKEY parameters specify the same file. psql requires that the client certificate and private key both be specified. If the certificate file contains the key then the same file may be specified in both environment variables. If the certificate and key are contained in separate files, then each may be specified individually.
In a more likely use case though, mutual authentication occurs - the client validates the server's certificate and the server validates the client's certificate, as follows:
PGSSLMODE=verify-full PGSSLCERT=/usr/local/firstworks/etc/sqlrclient.pem PGSSLKEY=/usr/local/firstworks/etc/sqlrclient.pem PGSSLROOTCERT=/usr/local/firstworks/etc/myca.pem psql -h sqlrserver.firstworks.com -U sqlruser
(.pem files are specified in this example, but on Windows systems, .pfx file or Windows Certificate Store references must be used. See The tlscert Parameter and The tlsca Parameter for details.)
In this example, the client provides a certificate for the server to validate, validates the host's certificate against the provided certificate authority, and validates the host's identity against the provided host name.
SQL Relay can validate the client's certificate, and reject clients which present invalid certificates, but cannot yet authenticate the user via the Subject Alternative Name or Common Name presented in the certificate in lieu of a PostgreSQL username. As such, a username and password must still be supplied for authentication in this configuration.
Performance Considerations
While TLS/SSL authenticated and encrypted sessions are substantially more secure than standard SQL Relay sessions, several factors contribute to a performance penalty:
- When establishing the secure session, a significant amount of data must be sent back and forth between the client and server over multiple network round-trips.
- Some TLS/SSL implementations impose a limit on the amount of data that can be sent or received at once, so more round trips may be required when processing queries.
- Without dedicated encryption hardware and a TLS/SSL implementation that supports it, the computation involved in encrypting and decrypting data can also introduce delays.
Any kind of full session encryption should be used with caution in performance-sensitive applications.
Foreign Backend
Since SQL Relay supports a variety of database back-ends, the app can also be redirected to any of these databases, instead of the PostgreSQL database it was originally written to use.
This is as simple as specifying a different database using the dbase attribute in the instance tag and specifying the appropriate database connection string in the string attribute of the connection tag.
<?xml version="1.0"?> <instances> <instance id="example" dbase="oracle"> <listeners> <listener protocol="postgresql" port="5432"/> </listeners> <connections> <connection string="user=scott;password=tiger;oracle_sid=ora1"/> </connections> </instance> </instances>
In this example, a PostgreSQL front-end provides PostgreSQL applications access to an Oracle back-end database.
Depending on the back-end, it might also be necessary to make some other configuration changes, as well, for example:
- In the instance tag:
- set translatebindvariables="yes"
- set the isolationlevel attribute
- In the string attribute of the connection tag:
- set autocommit=yes or autocommit=no
- set faketransactionblocks=yes
- implement a function that returns the last insert id and specify it using the lastinsertidfunction parameter
- set the identity parameter to override the database type
- set ignorespace=yes
- set the overrideschema parameter
- set the typemangling and/or tablemangling parameters
- use Query Translation modules
- use Result Set Translation modules
- use Error Translation modules
- use Session Queries
In your app, it might stil be necessary to modify some queries to use the syntax of the foreign database, or even update some code, but a full rewrite of the app should not be necessary.
Limitations
The implementation of the PostgreSQL protocol is likely sufficient for most applications, but it isn't 100% complete. Some notable limitations follow:
- Kerberos authentication and encryption are not supported.
- Multi-statement queries are not supported.
Multiple Protocols
A single instance of SQL Relay can also be configured to speak multiple protocols, granting access to the same database to applications which speak SQLRClient, MySQL, and/or PostgreSQL.
Basic Configuration
To enable SQL Relay to speak multiple protocols, add the appropriate listener tags:
<?xml version="1.0"?> <instances> <instance id="example" dbase="oracle"> <listeners> <listener protocol="sqlrclient" port="9000"/> <listener protocol="mysql" port="3306"/> <listener protocol="postgresql" port="5432"/> </listeners> <connections> <connection string="user=scott;password=tiger;oracle_sid=ora1"/> </connections> </instance> </instances>
In this configuration:
- The connection tag instructs the instance to log in to the ora1 oracle database as user scott with password tiger.
- The first listener tag instructs SQL Relay to load the sqlrclient and listen on port 9000 (the default SQL Relay port) for native SQL Relay clients.
- The second listener tag instructs SQL Relay to load the mysql and listen on port 3306 (the default MySQL port) for MySQL clients.
- The third listener tag instructs SQL Relay to load the postgresql and listen on port 5432 (the default PostgreSQL port) for PostgreSQL clients.
The instance can be started using:
sqlr-start -id example
and accessed from the local machine using the native SQL Relay command line client, as follows:
sqlrsh -host localhost -user scott -password tiger
or from the local machine using the MySQL command line client, as follows:
mysql --host=127.0.0.1 --user=scott --password=tiger
or from the local machine using the PostgreSQL command line client, as follows:
psql -h localhost -U scott
By default, SQL Relay listens on all available network interfaces, and can be accessed remotely by hostname. For example, if the server running SQL Relay is named sqlrserver then it can be accessed from another system using the native SQL Relay command line client, as follows:
sqlrsh -host sqlrserver -user scott -password tiger
or using the MySQL command line client, as follows:
mysql --host=sqlrserver --user=scott --password=tiger
or using the PostgreSQL command line client, as follows:
psql -h sqlrserver -U scott
The instance can be stopped using:
sqlr-stop -id example
Since this instance speaks the SQLRClient, MySQL, and PostgreSQL client-server protocols, clients that wish to use it may speak any of those client-server protocol. This means that most software written using the SQL Relay, MySQL, or PostgreSQL APIs, or written using a database abstraction layer which loads a driver for SQL Relay, MySQL, or PostgreSQL can access this instance. However, client programs for other databases (eg. the sqlplus command line programs, Oracle SQL Developer, SQL Server Management Studio, etc.) cannot access this instance.
In this example, a front-end that supports MySQL and PostgreSQL protocols provides access to an Oracle back-end database. As such some queries may have to be modified from their native MySQL and PostgreSQL syntax to use the syntax of the Oracle database.
Listener Options
When configured to support multiple protocols, each listener may be configured with the full set of attributes available for that protocol module.
For example:
- All modules support the host, port, and addresses attributes.
- All modules support the various tls attributes.
- The sqlrclient module supports the various krb attributes, but other modules do not.
Authentication/Encryption Options
The default authentication option is connect strings auth. This option works the same as it does when SQL Relay is configured to use a single protocol - a user is authenticated against the set of user/password combinations that SQL Relay is configured to use to access the database.
However, other auth modules can also be used. Each auth module knows to work with the corresponding protocol module.
<?xml version="1.0"?> <instances> <instance id="example" dbase="oracle"> <listeners> <listener protocol="sqlrclient" port="9000"/> <listener protocol="mysql" port="3306"/> <listener protocol="postgresql" port="5432"/> </listeners> <auths> <auth module="sqlrclient_userlist"> <user user="sqlruser" password="sqlrpassword"/> </auth> <auth module="mysql_userlist"> <user user="mysqluser" password="mysqlpassword"/> </auth> <auth module="postgresql_userlist"> <user user="postgresluser" password="postgresqlpassword"/> </auth> </auths> <connections> <connection string="user=scott;password=tiger;oracle_sid=ora1"/> </connections> </instance> </instances>
In this example:
- Native SQL Relay clients will be authenticated using the the sqlrclient_userlist auth module.
- MySQL clients will be authenticated using the the mysql_userlist auth module.
- PostgreSQL clients will be authenticated using the the postgresql_userlist auth module.
It can accessed from the local machine using the native SQL Relay command line client, as follows:
sqlrsh -host localhost -user sqlruser -password sqlrpassword
or from the local machine using the MySQL command line client, as follows:
mysql --host=127.0.0.1 --user=mysqluser --password=mysqlpassword
or from the local machine using the PostgreSQL command line client, as follows:
psql -h localhost -U postgresqluser
High Availabiltiy
In a high availability environment, SQL Relay can be deployed as a front-end to provide load balancing and failover for a set of replicated database servers or database cluster. Load balancing and failover can also be implemented over multiple SQL Relay servers.
Load Balancing and Failover With Replicated Databases or Database Clusters
In a database cluster or replication environment, SQL Relay can be configured to maintain a pool of connections to the various database nodes and distribute client sessions over the nodes. If an individual node fails, SQL Relay will attempt to reestablish connections to that node, while continuing to distribute client sessions over the remaining nodes.


In the configuration file, each connection tag defines a node to maintain connections to. In the following example, SQL Relay is configured to distribute over three Oracle nodes - ora1, ora2, and ora3
<?xml version="1.0"?>
<instances>
<instance id="example">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
<connection string="user=scott;password=tiger;oracle_sid=ora2"/>
<connection string="user=scott;password=tiger;oracle_sid=ora3"/>
</connections>
</instance>
</instances>
Any number of connection tags may be defined.
SQL Relay also supports disproportionate distribution of load. If some nodes can handle more traffic than others, then SQL Relay can be configured to send more traffic to the more capable nodes.
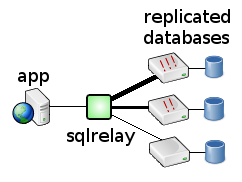
SQL Relay uses the connection tag's metric attribute to decide how many connections to open to each node.
<?xml version="1.0"?>
<instances>
<instance id="example">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1" metric="5"/>
<connection string="user=scott;password=tiger;oracle_sid=ora2" metric="15"/>
<connection string="user=scott;password=tiger;oracle_sid=ora3" metric="30"/>
</connections>
</instance>
</instances>
The metric attribute doesn't specify the number of connections to open to each node, but the higher the metric relative to the other metrics, the more connections to that node will be opened and maintained. For example, if the metric for the first node is twice as large as the metric for the second node, then SQL Relay will open twice as many connections to the first node as the second.
In the example above, 15 is 3 times 5, so 3 times as many connections will be opened to ora3 as to ora1. 30 is 6 times 5, so 6 times as many connections will be opened to ora3 as ora1. Since a total of 10 connections will be opened, 1 will be opened to ora1, 3 to ora2, and 6 to ora2.
Already-Load Balanced Databases
In a typical database cluster or replicated environment, the nodes are identifiable as separate hosts. However, when the nodes are located behind a load balancing appliance or running on an application cluster, such as Oracle RAC, SQL Relay cannot identity an individual node.
In these environments, if a node goes down, SQL Relay will attempt to re-establish the connection, but rather than failing until the node comes back up, the new connection will more likely just succeed to a different node in the cluster. Over time, this can lead to disproportionate load balancing, with a bias toward nodes that have never gone down.
SQL Relay manages this by "shuffling" the connections periodically. Every so often, each database connection is re-established, giving that connection a chance to be re-established to a node that may have gone down but is now back up.
To indicate to SQL Relay that the nodes are already-load balanced, and need to be "shuffled" periodically, only one connection tag should be used, with the behindloadbalancer attribute set to "yes".
<?xml version="1.0"?>
<instances>
<instance id="example">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=orarac" behindloadbalancer="yes"/>
</connections>
</instance>
</instances>
Master-Slave Query Routing
The load balancing scenarios described above all assume that master-master replication is being used. SQL Relay supports master-slave replication as well.
In a master-slave replication environment, SQL Relay can be configured to route DML and DDL queries to the master and distribute selects over the slaves.

This actually requires 3 instances of SQL Relay. One to connect to the master, one to connect to the slaves, and a third to route queries to the first two.
<?xml version="1.0"?>
<instances>
<!-- This instance maintains connections to the "master" MySQL database
on the masterdb machine. This instance only listens on the
unix socket /tmp/master.socket and thus cannot be connected to
by clients from another machine. -->
<instance id="master" socket="/tmp/master.socket" dbase="mysql">
<connections>
<connection string="user=masteruser;password=masterpassword;host=masterdb;db=master;"/>
</connections>
</instance>
<!-- This instance maintains connections to 4 "slave" MySQL databases
on 4 slave machines. This instance only listens on the unix
socket /tmp/slave.socket and thus cannot be connected to by
clients from another machine. -->
<instance id="slave" socket="/tmp/slave.socket" dbase="mysql">
<connections>
<connection string="user=slaveuser;password=slavepassword;host=slavedb1;db=slave;"/>
<connection string="user=slaveuser;password=slavepassword;host=slavedb2;db=slave;"/>
<connection string="user=slaveuser;password=slavepassword;host=slavedb3;db=slave;"/>
<connection string="user=slaveuser;password=slavepassword;host=slavedb3;db=slave;"/>
</connections>
</instance>
<!-- This instance sends DML (insert,update,delete) and
DDL (create/delete) queries to the "master" SQL Relay instance
which, in turn, sends them to the "master" database.
This instance sends any other queries to the "slave" SQL Relay
instance which, in turn, distributes them over the "slave"
databases. -->
<instance id="router" dbase="router">
<auths>
<auth module="sqlrclient_userlist">
<user user="routeruser" password="routerpassword"/>
</auth>
</auths>
<routers>
<!-- send all DML/DDL queries to "master" -->
<router module="regex" connectionid="master">
<pattern pattern="^drop "/>
<pattern pattern="^create "/>
<pattern pattern="^insert "/>
<pattern pattern="^update "/>
<pattern pattern="^delete "/>
</router>
<!-- send all other queries to "slave" -->
<router module="regex" connectionid="slave">
<pattern pattern=".*"/>
</router>
</routers>
<connections>
<connection connectionid="master" string="socket=/tmp/master.socket;user=masteruser;password=masterpassword"/>
<connection connectionid="slave" string="socket=/tmp/slave.socket;user=slaveuser;password=slavepassword"/>
</connections>
</instance>
</instances>
The first two instances use familiar configuration options, but the third uses a dbtype of "router" and uses router tags to define query routing rules.
(Note the module attribute of the router tag. SQL Relay is highly modular, and many advanced features, including query routing, are implemented by loadable modules.)
(Note also the use of a notifications tag. See Notifications below for more information.)
Each router tag defines a connectionid to send the query to and a set of regular expression patterns to match. Queries that match the set of patterns defined in the pattern tags are sent to the instance of SQL Relay designated by the connectionid in the router tag.
The three instances can be started using:
sqlr-start -id master sqlr-start -id slave sqlr-start -id router
( NOTE: When installed from packages, SQL Relay may have to be started and stopped as root.)
Client applications should connect to the router instance rather than the master or slave instances.
sqlrsh -host sqlrserver -user routeruser -password routerpassword
Front-End Load Balancing and Failover
If you are building out a high availability environment, or if your pool of application servers is just sufficiently large, you might want to set up a pool of SQL Relay servers between your application servers and the database, and distribute client applications over the pool using host randomization, a load balancing appliance, or round-robin DNS.
Host Randomization
Since version 2.0.1, host randomization can be used to distribute SQL Relay client sessions over a pool of SQL Relay hosts.
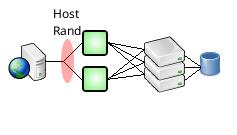
Any application which uses one of the SQL Relay Native APIs, including applications which use the SQL Relay driver for a database abstraction layer, can be configured to connect to a set of servers instead of just a single server by specifying the host or server parameter as a comma-separated set of hosts. Internally, the API will attempt to connect to a random host in the set, until the attempt succeeds, or there are no more hosts left to try.
For example, the sqlrsh command line tool can be configured to connect to sqlr01, sqlr02, and sqlr03 as follows:
sqlrsh -host sqlr01,sqlr02,sqlr03 -user scott -password tiger
Other SQL Relay command line tools can be configured similarly.
A program written using the SQL Relay Native API for C++ can be configured to connect to the same set of hosts as follows:
sqlrconnection *con=new sqlrconnection("sqlr01,sqlr02,sqlr03",9000,NULL,"scott","tiger",0,1);
Other SQL Relay Native APIs can be configured similarly.
A program that uses the SQL Relay driver for ODBC can be configured as follows:
[sqlrexample] Description=Connection to SQL Relay Pool Driver=SQLRelay Server=sqlr01,sqlr02,sqlr03 Port=9000 Socket= User=scott Password=tiger
A program that uses the SQL Relay driver for PHP PDO can be configured as follows:
my $dbh=DBI->connect("DBI:SQLRelay:host=sqlr01,sqlr02,sqlr03;port=9000","scott","tiger");
Programs that use SQL Relay drivers for other database abstraction layers can be configured similarly.
Load Balancing Appliance
Multiple instances of SQL Relay can be placed behind a load balancing appliance.

In this illustration, the load balancing appliance is shown as a single machine, but in a true HA environment, there would be 2 or more appliances sharing a virtual IP. Alternatively, rather than using an appliance, SQL Relay can be run on an application server cluster such as Linux Virtual Server.
Round-Robin DNS
Round-robin DNS can be also be used to distribute clients over multiple SQL Relay servers.

In a round-robin DNS scenario, multiple IP addresses are assigned to the same host name. The SQL Relay client is then configured to connect to that host. When it requests the IP addresses for the host, the client receives all of the IP addresses assigned to it, rather than just a single address.
Round-robin DNS is so-called because, traditionally, the order of the IP addresses returned on successive requests alternated reliably, in round-robin fashion. This behavior persists in many environments, but it is no longer guaranteed, as many modern DNS resolvers sort the list and return the IP addresses in the same order, every time. SQL Relay clients randomize the list though, and try to connect to each of the IP addresses, one-at-a-time, until they succeed. Doing so provides both load balancing and failover without requiring an appliance or application server cluster.
Security Features
SQL Relay offers several features to enhance security.
Front-End Encryption and Secure Authentication
When configured to use the SQLRClient protocol (the default), SQL Relay supports Kerberos and Active Directory Encryption and Authentication and TLS/SSL Encryption and Authentication between the SQL Relay client and SQL Relay server.
When configured to use the MySQL or PostgreSQL protocols, SQL Relay supports TLS/SSL encryption and authentication between the SQL Relay client and SQL Relay server. See MySQL TLS/SSL Encryption and Authentication and PostgreSQL TLS/SSL Encryption and Authentication for details.
Back-End Encryption and Secure Authentication
SQL Relay also supports TLS/SSL Encryption and Authentication between the SQL Relay server and some databases.
The configuration details differ between databases though.
Oracle
Modern Oracle databases support the following TLS/SSL features:
- Encryption
- Certificate Validation
- Distinguished Name Validation
- Mutual Authentication
Configuring SQL Relay to use TLS/SSL encryption and authentication with an Oracle database involves:
- Configuring SQL*Net on the database server to support secure connections
- Configuring SQL*Net on the SQL Relay server to support secure connections
- Telling SQL Relay to use an oracle_sid that refers to a secure connection
Most of the configuration on the SQL Relay server is done outside of SQL Relay itself.
Configuring SQL*Net involves setting up Oracle Wallets, which is a relatively complex process. See Oracle TLS/SSL Encryption Tutorials for more information. Once that is done though, the SQL Relay configuration is relatively simple.
In this example, oratls refers to a TLS/SSL-secured entry in the tnsnames.ora file (usually $ORACLE_HOME/network/admin/tnsnames.ora):
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="oracle">
<connections>
<connection string="user=scott;password=tiger;oracle_home=/u01/app/oracle/product/12.1.0;oracle_sid=oratls"/>
</connections>
</instance>
</instances>
In this example, there is no tnsnames.ora file, so the oracle_sid is set directly to a tnsnames-style expression that describes a TLS/SSL-secured connection:
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="oracle">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=(DESCRIPTION = (ADDRESS = (PROTOCOL = TCPS)(HOST = examplehost)(PORT = 2484)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ora1)))"/>
</connections>
</instance>
</instances>
Note the TCPS protocol and port 2848. Also note that the SERVICE_NAME is still set to ora1, rather than oratls.
This example adds distinguished name validation:
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="oracle">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=(DESCRIPTION = (ADDRESS = (PROTOCOL = TCPS)(HOST = examplehost)(PORT = 2484)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ora1)) (SECURITY = (SSL_SERVER_CERT_DN = "CN=examplehost.yourdomain.com")))"/>
</connections>
</instance>
</instances>
In this case, the database server's certificate is expected to present the distinguished name: CN=examplehost.yourdomain.com
Microsoft SQL Server (via FreeTDS)
Modern Microsoft SQL Server databases support the following TLS/SSL features:
- Encryption
- Certificate Validation
- Common Name Validation
Microsoft SQL Server does not support Mutual Authentication over TLS/SSL.
Configuring SQL Relay to use TLS/SSL encryption and authentication with a Microsoft SQL Server database via FreeTDS involves:
- Installing a certificate and key on the database server
- Configuring FreeTDS on the SQL Relay server to support secure connections
- Telling SQL Relay to use a FreeTDS server entry that refers to a secure connection
Modern Microsoft SQL Server databases support encryption by default, and enable it upon request. However, a certificate must be installed on the database server to support authentication. This process can be tricky because SQL Server places some specific requirements on the certificate:
- The common name MUST match the fully qualified domain name of the database server (host name + primary DNS suffix).
- ...but Windows servers are commonly configured without a primary DNS suffix.
- The Enhanced Key Usage property MUST include Server Authentication.
- Or, in openssl terms: the extendedKeyUsage extension must include serverAuth in the extfile used to generate the certificate signing request.
See TLS/SSL Encryption with MS SQL Server and FreeTDS for more information.
Most of the configuration on the SQL Relay server is done outside of SQL Relay itself, in the freetds.conf file (usually /etc/freetds.conf or /usr/local/etc/freetds.conf).
In this example, FreeTDS is configured to require an encrypted connection to the database:
[FREETDSSERVER] host = examplehost port = 1433 tds version = 7.1 client charset = UTF-8 encryption = require
Note that the tds version is 7.1 or higher. Version 7.0 doesn't support encryption.
In this example, FreeTDS is also configured to validate the database server's certificate against the CA cert /etc/ca.pem (but does not validate the common name):
[FREETDSSERVER] host = examplehost port = 1433 tds version = 7.1 client charset = UTF-8 encryption = require ca file = /etc/ca.pem check certificate hostname = no
In this example, FreeTDS is also configured to validate that the common name in the database server's certificate matches the database server's host name:
[FREETDSSERVER] host = examplehost.yourdomain.com port = 1433 tds version = 7.1 client charset = UTF-8 encryption = require ca file = /etc/ca.pem check certificate hostname = yes
Note that the host parameter has been updated to specify a fully qualified domain name. This is the value that the common name will be compared to.
The SQL Relay configuration is no different than the configuration for an insecure connection. In this example, FREETDSSERVER refers to the FreeTDS FREETDSSERVER entry configured above:
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="freetds">
<connections>
<connection string="server=FREETDSSERVER;user=freetdsuser;password=freetdspassword;db=freetdsdb"/>
</connections>
</instance>
</instances>
MySQL/MariaDB
Modern MySQL/MariaDB databases support the following TLS/SSL features:
- Encryption
- Certificate Validation
- Common Name Validation
MySQL/MariaDB does not support Mutual Authentication over TLS/SSL.
Configuring SQL Relay to use TLS/SSL encryption and authentication with a MySQL/MariaDB database involves:
- Installing a certificate and key on the database server
- Configuring the SQL Relay server to support encryption and/or authentication
- Installing CA certs and revocation lists, as necessary, on the SQL Relay server
MySQL/MariaDB has supported TLS/SSL encryption and authentication since version 4.0, and encryption has been enabled by default since version 5.7. Older versions require host configuration to enable encryption though, and a certificate must be installed on the database server to support authentication. See Using Encrypted Connections for more information.
On the SQL Relay server, most of the configuration is done in the SQL Relay configuration file, in the string attribute of the connection tag.
The following example requires an encrypted connection:
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="mysql">
<connections>
<connection string="user=mysqluser;password=mysqlpassword;host=mysqlhost;db=mysqldb;sslmode=require"/>
</connections>
</instance>
</instances>
The following connection string options are supported:
- sslmode - The ssl mode of the connection.
- disable - Don't use an encrypted connection.
- prefer - Use an encrypted connection if the database supports it.
- require - Require an encrypted connection.
- verify-ca - Require an encrypted connection and validate the server's certificate.
- verify-full - Require an encrypted connection, validate the server's certificate, and validate that the common name in the server's certificate matches the server's host name.
- tlsversion - the TLS version to use
- TLSv1
- TLSv1.1
- TLSv1.2
- Any more recent version of TLS, as supported by and enabled in the underlying MySQL/MariaDB client/server.
- If left blank or omitted, then the highest supported version is negotiated.
- sslkey - The full path name of an ssl key file (eg. /etc/certs/key.pem).
- sslcert - The full path name of an ssl certificate file (eg. /etc/certs/cert.pem).
- sslcipher - A list of permissable ciphers to use for SSL encryption. Only necessary if you want to restrict which cipers to use.
- sslca - The full path name of an SSL CA certificate to add to the list of trusted CA certificates to validate the host's certificate against (eg. /etc/certs/ca.pem).
- sslcapath - The full path name to a directory that contains a set of trusted SSL CA certificates to add to the list of trusted CA certificates to validate the host's certificate against (eg. /etc/certs/ca).
- sslcrl - The full path name of an SSL certificate revocation list (eg. /etc/certs/crl.pem).
- sslcrlpath - The full path name of a directory that contains a set of SSL certificate revocation lists (eg. /etc/certs/crl).
The following example also validates the database server's certificate against the CA cert /etc/ca.pem (but does not validate the common name):
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="mysql">
<connections>
<connection string="user=mysqluser;password=mysqlpassword;host=mysqlhost;db=mysqldb;sslmode=verify-ca;sslca=/etc/ca.pem"/>
</connections>
</instance>
</instances>
The following example also validates that the common name in the database server's certificate matches the database server's host name:
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="mysql">
<connections>
<connection string="user=mysqluser;password=mysqlpassword;host=mysqlhost.yourdomain.com;db=mysqldb;sslmode=verify-full;sslca=/etc/ca.pem"/>
</connections>
</instance>
</instances>
Note that the host parameter has been updated to specify a fully qualified domain name. This is the value that the common name will be compared to.
PostgreSQL
Modern PostgreSQL databases support the following TLS/SSL features:
- Encryption
- Certificate Validation
- Common Name Validation
- Mutual Authentication
Configuring SQL Relay to use TLS/SSL encryption and authentication with a PostgreSQL database involves:
- Configuring the database server to support secure connections
- Installing a certificate on the database server
- Configuring the SQL Relay server to support secure connections
- Installing a certificate on the SQL Relay server
- Configuring the database server to support encryption and/or authentication
- Installing certificate, key, CA certs, and revocation lists, as necessary, on the database server
- Configuring the SQL Relay server to support encryption and/or authentication
- Installing certificate, key, CA certs, and revocation lists, as necessary, on the SQL Relay server
PostgreSQL has supported TLS/SSL encryption and authentication since at least version 7.1. Enabling encryption and/or authentication is straightforward. See Secure TCP/IP Connections with SSL for more information.
On the SQL Relay server, most of the configuration is done by adding an sslmode parameter to the string attribute of the connection tag, in the SQL Relay configuration file.
The following example requires an encrypted connection:
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="postgresql">
<connections>
<connection string="user=postgresqluser;password=postgresqlpassword;host=postgresqlhost;db=postgresqldb;sslmode=require"/>
</connections>
</instance>
</instances>
The following sslmode options are supported:
- disable - Don't use an encrypted connection.
- allow - Allow an encrypted connection if the database supports it.
- prefer - Use an encrypted connection if the database supports it.
- require - Require an encrypted connection.
- verify-ca - Require an encrypted connection and validate the server's certificate.
- verify-full - Require an encrypted connection, validate the server's certificate, and validate that the common name in the server's certificate matches the server's host name.
If sslmode is set to any value other than disable, then certificate and key files must be present as:
- ~/.postgresql/postgresql.crt
- ~/.postgresql/postgresql.key
(where ~/ refers to the home directory of the user that sqlrelay is configured to run as)
If sslmode is set to verify-ca or verify-full then a CA cert file must be present as:
- ~/.postgresql/root.crt
Optionally, a certificate revocation list may also be present as:
- ~/.postgresql/root.crl
See SSL Client File Usage for more information about file names and locations.
The following example also validates the database server's certificate (but does not validate the common name):
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="postgresql">
<connections>
<connection string="user=postgresqluser;password=postgresqlpassword;host=postgresqlhost;db=postgresqldb;sslmode=verify-ca"/>
</connections>
</instance>
</instances>
The following example also validates that the common name in the database server's certificate matches the database server's host name:
<?xml version="1.0"?>
<instances>
<instance id="example" dbase="postgresql">
<connections>
<connection string="user=postgresqluser;password=postgresqlpassword;host=postgresqlhost.yourdomain.com;db=postgresqldb;sslmode=verify-full"/>
</connections>
</instance>
</instances>
Note that the host parameter has been updated to specify a fully qualified domain name. This is the value that the common name will be compared to.
Run-As User and Group
When a non-root user runs sqlr-start, the SQL Relay server runs as that user and as the primary group of that user.
When root runs sqlr-start, the SQL Relay server runs as a more secure user and group, usually nobody/nobody when built from source, or sqlrelay/sqlrelay when installed from packages.
However, the runasuser and runasgroup attributes can be used to control what user and group the SQL Relay server runs as.
<?xml version="1.0"?> <instances> <instance id="example" ... runasuser="exampleuser" runasgroup="examplegroup" ...> ... </instance> </instances>
There are several important considerations when setting runasuser/runasgroup:
- runasuser is only effective if sqlr-start runs as root.
- runasgroup only effective if sqlr-start runs as a member of the group, or by root.
- All SQL Relay configuration files, and any appropriate database configuration files (such as Oracle's tnsnames.ora and SAP/Sybase's interfaces file) must be readable by the runasuser/runasgroup. Otherwise various things will fail, most notably, dynamic scaling.
- SQL Relay must be able to write to "run" and "log" directories. However, when installed from packages, the /var/run/sqlrelay and /var/log/sqlrelay directories are owned by sqlrelay/sqlrelay and have fairly restrictive 755 permissions. Thus, the permissions on these directories must be manually changed if runasuser or runasgroup are set to any value other than "sqlrelay". This is not an issue if SQL Relay is built from source, and is not an issue on Windows.
IP Filtering
By default, clients from any IP address are allowed to connect to the SQL Relay srever. However, the deinedips and allowedips attributes can be used to restrict the set of IP addresses that clients can connect from.
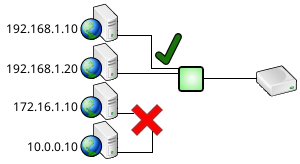
The deniedips attribute can be configured with a regular expression indicating which IP address will be denied access. The allowedips attribute can also be configured with a regular expression to override the deniedips attribute.
For example, to deny all clients except clients connecting from the 192.168.2.0 and 64.45.22.0 networks:
<?xml version="1.0"?> <instances> <instance id="example" ... deniedips=".*" allowedips="(192\.168\.2\..*|64\.45\.22\..*)" .../> ... </instance> </instances>
Password Files
Password files enable you to store passwords in external files, rather than directly in the config file. Passwords can then be secured by setting a more restrictive set of permissions on the files containing the passwords than on the config file itself.
( NOTE: If runasuser/runasgroup are used, then password files must be readable by the runasuser/runasgroup. Otherwise various things will fail, most notably, dynamic scaling.)
Password files are supported by all userlist auth modules, including sqlrclient_userlist, mysql_userlist and postgresql_userlist, as well as in database connect strings.
To use password files, put each password in an external file, and enclose the full path of the file in square brackets as follows:
<?xml version="1.0"?>
<instances>
<instance id="example">
<auths>
<auth module="sqlrclient_userlist">
<user user="oneuser" password="[/usr/local/firstworks/etc/oneuser.pwd]"/>
<user user="anotheruser" password="[/usr/local/firstworks/etc/anotheruser.pwd]"/>
<user user="yetanotheruser" password="[/usr/local/firstworks/etc/yetanotheruser.pwd]"/>
</auth>
</auths>
<connections>
<connection string="user=ora1user;password=[/usr/local/firstworks/etc/ora1user.pwd];oracle_sid=ora1"/>
<connection string="user=ora2user;password=[/usr/local/firstworks/etc/ora2user.pwd];oracle_sid=ora2"/>
<connection string="user=ora3user;password=[/usr/local/firstworks/etc/ora3user.pwd];oracle_sid=ora3"/>
</connections>
</instance>
</instances>
In this example...
The contents of the file /usr/local/firstworks/etc/oneuser.pwd would be used to authenticate oneuser, and could contain the text:
onepassword
The contents of the file /usr/local/firstworks/etc/anotheruser.pwd would be used to authenticate anotheruser, and could contain the text:
anotherpassword
The contents of the file /usr/local/firstworks/etc/yetanotheruser.pwd would be used to authenticate yetanotheruser, and could contain the text:
yetanotherpassword
The contents of the file /usr/local/firstworks/etc/ora1user.pwd would contain the password for ora1user, perhaps containing the text:
ora1password
The contents of the file /usr/local/firstworks/etc/ora2user.pwd would contain the password for ora2user, perhaps containing the text:
ora2password
The contents of the file /usr/local/firstworks/etc/ora3user.pwd would contain the password for ora3user, perhaps containing the text:
ora3password
( NOTE: Trailing whitespace is ignored when passwords are stored in external files.)
If you would prefer not to use full pathnames inside of each set of square brackets, then you can specify a passwordpath attribute in the instance tag, as follows:
<?xml version="1.0"?>
<instances>
<instance id="example" passwordpath="/usr/local/firstworks/etc">
<auths>
<auth module="sqlrclient_userlist">
<user user="oneuser" password="[oneuser.pwd]"/>
<user user="anotheruser" password="[anotheruser.pwd]"/>
<user user="yetanotheruser" password="[yetanotheruser.pwd]"/>
</auth>
</auths>
<connections>
<connection string="user=ora1user;password=[ora1user.pwd];oracle_sid=ora1"/>
<connection string="user=ora2user;password=[ora2user.pwd];oracle_sid=ora2"/>
<connection string="user=ora3user;password=[ora3user.pwd];oracle_sid=ora3"/>
</connections>
</instance>
</instances>
In this case, the path /usr/local/firstworks/etc will be searched for the files oneuser.pwd, anotheruser.pwd, yetanotheruser.pwd, ora1user.pwd, ora2user.pwd, and ora3user.pwd.
Password Encryption
Password encryption enables you to store passwords in the configuration file in a manner that makes them not directly readable. Passwords for both SQL Relay users and database users may be encrypted.
Encryption and decryption are implemented by loadable modules. The passwordencryptions section of the configuration file indicates which modules to load, and attributes in the user and connection tags indicate which module to use with the password defined in that same tag.
For example, to use the rot module, which encrypts by performing a simple character rotation:
<?xml version="1.0"?> <instances> <instance ...> <passwordencryptions> <passwordencryption module="rot" id="rot13enc" count="13"/> </passwordencryptions> <auths> <auth module="sqlrclient_userlist"> <user user="sqlruser" password="fdyecnffjbeq" passwordencryptionid="rot13enc"/> </auth> </auths> <connections> <connection connectionid="db" string="user=oracleuser;password=benpyrcnffjbeq;..." passwordencryptionid="rot13enc"/> </connections> </instance> </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
In this example, the id and count attributes configure the rot module. "13" tells the module to rotate by 13 characters. The id attribute assigns this particular module configuration an id that will be referenced by user and connection tags. The id attribute is mandatory.
Note that the password in the user tag is encrypted (unencrypted, it would just be "sqlrpassword") and that the password in the string attribute of the connection tag is also encrypted (unencrypted, it would just be "oraclepassword"). A command line program (described below) is provided to encrypt passwords.
Note also that the passwordencryptionid attribute in both tags refers to the id of the module as set using the id attribute in the passwordencryption tag ( rot13enc ), not the module name ( rot ).
Password encryption modules may be "stacked". It is possible to load multiple modules and use each one with a different password. For example, you might want to use the rot module with a count of 13 for the SQL Relay password and a count of 10 for the database password.
<?xml version="1.0"?> <instances> <instance ...> <passwordencryptions> <passwordencryption module="rot" id="rot13enc" count="13"/> <passwordencryption module="rot" id="rot10enc" count="10"/> </passwordencryptions> <auths> <auth module="sqlrclient_userlist"> <user user="sqlruser" password="fdyecnffjbeq" passwordencryptionid="rot13enc"/> </auth> </auths> <connections> <connection connectionid="db" string="user=oracleuser;password=ybkmvozkccgybn;..." passwordencryptionid="rot10enc"/> </connections> </instance> </instances>
Encryption modules may be either two-way or one-way. Two-way encryption modules can both encrypt and decrypt a password. One-way encryption modules can only encrypt a password, not decrypt it.
As such, SQL Relay can use either one-way or two-way encryption to encrypt passwords for SQL Relay users. However, only two-way encryption can only be used to encrypt passwords for database users.
The command line tool sqlr-pwdenc is provided to help encrypt passwords for inclusion in the configuration file. Given an encryption module and password, it will print out the encrypted password.
sqlr-pwdenc [-config configfile] -id id -pwdencid passwordencryptionid -password password
- configfile - optional and refers to the configuration file
- id - the instance within the configuration file to look for the specified password encryption module definition
- passwordencryptionid - the id of the password encryption module to use
- password - the password to encrypt
For example:
$ sqlr-pwdenc -id example -pwdencid rot13enc -password oraclepassword benpyrcnffjbeq
The resulting string "benpyrcnffjbeq" can now be put in the configuration file as the password.
There is one final thing to note. SQL Relay command line client programs like sqlrsh and sqlr-import take an -id option. The -id option causes the program to open the configuration file and extract the port, socket, user and password from the specified instance. If the password is two-way encrypted then this will still work. However, if the password is one-way encrypted, then this will fail. So, when using the -id option with a one-way encrypted password, you must also use the -user and -password option.
For example, rather than just using:
sqlrsh -id example
You should use:
sqlrsh -id example -user sqlruser -password sqlrpassword
Currently, the following password encryption modules are available in the standard SQL Relay distribution:
- rot
- md5
- sha1
- sha256
- des
Custom modules may also be developed. For more information, please contact dev@firstworks.com. 

rot
The rot module is a two-way encryption module that performs a character rotation, similar to the popular ROT13 algorithm, though it can rotate by any amount specified in the count attribute, not just 13 and rotates digits as well as upper and lower-case characters.
<?xml version="1.0"?> <instances> <instance ...> <passwordencryptions> <passwordencryption module="rot" id="rot13enc" count="13"/> </passwordencryptions> <auths> <auth module="sqlrclient_userlist"> <user user="sqlruser" password="fdyecnffjbeq" passwordencryptionid="rot13enc"/> </auth> </auths> <connections> <connection connectionid="db" string="user=oracleuser;password=benpyrcnffjbeq;..." passwordencryptionid="rot13enc"/> </connections> </instance> </instances>
Since the ROT algorithm is two-way, it can be used to encrypt passwords for both SQL Relay users and database users.
md5
The md5 module is a one-way encryption module that encrypts the password using the MD5 algorithm. This module has no parameters.
<?xml version="1.0"?> <instances> <instance ...> <passwordencryptions> <passwordencryption module="md5" id="md5enc"/> </passwordencryptions> <auths> <auth module="sqlrclient_userlist"> <user user="sqlruser" password="b3553e9ee74fc545fb632f92e0a5f1ea" passwordencryptionid="md5enc"/> </auth> </auths> ... </instance> </instances>
Since the MD5 algorithm is one-way, it can be used to encrypt passwords for SQL Relay users, but not database users.
sha1
The sha1 module is a one-way encryption module that encrypts the password using the SHA-1 algorithm. This module has no parameters.
<?xml version="1.0"?> <instances> <instance ...> <passwordencryptions> <passwordencryption module="sha1" id="sha1enc"/> </passwordencryptions> <auths> <auth module="sqlrclient_userlist"> <user user="sqlruser" password="75e0c08dceb871fbf39ccf3049c6df1e60984d9a" passwordencryptionid="sha1enc"/> </auth> </auths> ... </instance> </instances>
Since the SHA-1 algorithm is one-way, it can be used to encrypt passwords for SQL Relay users, but not database users.
sha256
The sha256 module is a one-way encryption module that encrypts the password using the SHA-256 algorithm. This module has no parameters.
<?xml version="1.0"?> <instances> <instance ...> <passwordencryptions> <passwordencryption module="sha1" id="sha1enc"/> </passwordencryptions> <auths> <auth module="sqlrclient_userlist"> <user user="sqlruser" password="fb3869b97931d922ab4f6060ab4958f17dc05613f0ff6c584ce4000af5fab460" passwordencryptionid="sha1enc"/> </auth> </auths> ... </instance> </instances>
Since the SHA-256 algorithm is one-way, it can be used to encrypt passwords for SQL Relay users, but not database users.
des
The des module is a one-way encryption module that encrypts the password using the DES algorithm using a salt specified in the salt attribute. The salt is required and must be a 2 digit alphanumeric code.
<?xml version="1.0"?> <instances> <instance ...> <passwordencryptions> <passwordencryption module="crypt" id="cryptenc" salt="sr"/> </passwordencryptions> <auths> <auth module="sqlrclient_userlist"> <user user="sqlruser" password="nIdCgucqUQg" passwordencryptionid="cryptenc"/> </auth> </auths> ... </instance> </instances>
Since the DES algorithm is one-way, it can be used to encrypt passwords for SQL Relay users, but not database users.
aes128
The aes128 module is a two-way encryption module that performs AES128 (CBC) encryption/decryption.
<?xml version="1.0"?> <instances> <instance ...> <passwordencryptions> <passwordencryption module="aes128" id="aes128enc" key="000102030405060708090a0b0c0d0e0f"/> </passwordencryptions> <auths> <auth module="sqlrclient_userlist"> <user user="sqlruser" password="1f7be0255e24783696a1783114e28667320ecef9537b5da48c19dbfa793fbcaf" passwordencryptionid="aes128enc"/> </auth> </auths> <connections> <connection connectionid="db" string="user=oracleuser;password=153b3125b0ce225e06c3f61eb68a2b062eb6bdc17db4894620f8067cfec4c1bf;..." passwordencryptionid="aes128enc"/> </connections> </instance> </instances>
Since the aes128 algorithm is two-way, it can be used to encrypt passwords for both SQL Relay users and database users.
The key attribute of the passwordencryption element contains a hexidecimal representation of the 128 bit (16 byte) key. The password attribute of the user element, and password parameter of the string attribute of the connection element contain hexidecimal representations of the encrypted passwords.
Note that multiple runs of sqlr-pwdenc with the same key and password will generate different results each time. This is the correct behavior. The first 128 bits (16 bytes) of the encrypted password are the "initialization vector" - a randomly generated string used in conjunction with the key to encrypt/decrypt the password. This vector is generated each time sqlr-pwdenc is run. Successive runs of sqlr-pwdenc generate different initialization vectors, and thus different encrypted passwords.
Connection Schedules
Connection schedules enable the SQL Relay server to control when users are allowed to access the database.
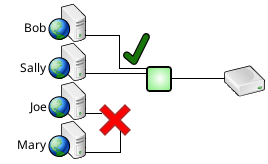
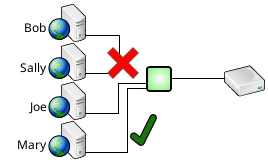
Connection schedules are implemented by loadable modules. The schedules section of the configuration file indicates which modules to load and what parameters to use when executing them.
<?xml version="1.0"?> <instances> <instance ...> ... <schedules> <!-- allow these users during business hours --> <schedule module="cron_userlist" default="deny"> <users> <user user="dmuse"/> <user user="kmuse"/> <user user="imuse"/> <user user="smuse"/> </users> <rules> <allow when="* * * 2-5 8:00-11:59,13:00-16:59"/> </rule> </schedule> </schedules> ... </instance> </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
All schedule modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All schedule modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Connection schedule modules can be "stacked". Multiple different modules may be loaded, and multiple instances of the same type of module, with different configurations, may also be loaded.
<?xml version="1.0"?> <instances> <instance ...> ... <schedules> <!-- allow these users during business hours --> <schedule module="cron_userlist" default="deny"> <users> <user user="imuse"/> <user user="smuse"/> </users> <rules> <allow when="* * * 2-5 8:00-11:59,13:00-16:59"/> </rule> </schedule> <!-- allow these users at any time --> <schedule module="cron_userlist" default="deny"> <users> <user user="dmuse"/> <user user="kmuse"/> </users> <rules> <allow when="* * * * *"/> </rule> </schedule> </schedules> ... </instance> </instances>
At startup, the SQL Relay server creates instances of the specified schedule modules and initializes them. When a client connects, the server passes the supplied credentials to each module, in the order that they were specified in the config file. Each module applies its rules to the specified user. If a module denies access to a user then the remaining modules are ignored. If the user makes it through all modules without being denies access, then the user is allowed access.
Currently, only the ''cron_userlist'' connection schedule module is available in the standard SQL Relay distribution. Custom modules may be developed though. For more information, please contact dev@firstworks.com.
cron_userlist
The cron_userlist module enables you to define a connection schedule for a list of users, using a cron-like syntax.
Note though, that the time-and-date fields have different meanings from traditional cron.
An example configuration follows.
<?xml version="1.0"?> <instances> <instance ...> ... <schedules> <!-- allow these users during business hours --> <schedule module="cron_userlist" default="deny"> <users> <user user="dmuse"/> <user user="kmuse"/> <user user="imuse"/> <user user="smuse"/> </users> <rules> <allow when="* * * 2-5 8:00-11:59,13:00-16:59"/> </rule> </schedule> </schedules> ... </instance> </instances>
In this example, the module denies access to all users by default, but then allows access to the dmuse, kmuse, imuse, and smuse users during business hours. In this case, business hours are defined as:
- every year
- every month
- every day of the month
- between days 2-5 (Monday-Friday) of the week
- between 8:00AM and 11:59AM and 1:00PM and 4:59PM
Another example configuration follows.
<?xml version="1.0"?> <instances> <instance ...> ... <schedules> <!-- deny these users during non-business hours --> <schedule module="cron_userlist" default="allow"> <users> <user user="dmuse"/> <user user="kmuse"/> <user user="imuse"/> <user user="smuse"/> </users> <rules> <deny when="* * * 2-5 00:00-7:59,12:00-12:59,17:00-23:59"/> <deny when="* * * 1,7 *"/> </rules> </schedule> </schedules> ... </instance> </instances>
In this example, the module allows access to all users by default, but then denies access to the dmuse, kmuse, imuse, and smuse users during non-business hours. In this case, non-business hours are defined as:
- every year
- every month
- every day of the month
- between days 2-5 (Monday-Friday) of the week
- between 12:00AM and 7:59AM
- between 12:00PM and 12:59PM
- between 5:00PM and 11:59PM
- on days 1 and 7 (Saturday and Sunday) of the week, at all hours
The users tag defines a list of users to apply the schedule to. It may contain any number of user tags.
The user tags support the following attributes:
- user - the name of a user or * meaning "all users"
If a user does not appear in this list then it is granted access at any time. If a user appears in the list then the schedule will be applied to that user.
The default attribute of the schedule tag defines the default rule.
- allow - allow access to the list of users unless they are denied access by the set of rules
- deny - deny access to the list of users unless they are allowed access by the set of rules
The rules tag defines the list of rules that modify the default behavior. It may contain allow or deny tags.
The allow and deny tags support the following attributes:
- when - the years, months, days of month, days of week, and times of day that the rule applies to
The format of the when attribute is cron-like. There are 5 fields, separated by spaces.
Note again though, that the time-and-date fields have different meanings from traditional cron.
The fields represent, in order:
- years
- months (where 1=January)
- days of the month
- days of the week (where 1=Sunday)
- times of day, in 24-hour format
In each field, ranges may be specified with a dash, and sets may be separated by commas. A * means "all possible values".
For example:
All day, every day, at any time of day:
* * * * *
All day, every month, on the 1st, 3rd through 5th, 8th, and 10th through 12th of the month:
* * 1,3-5,8,10-12 * *
Every day from 8:00AM through 11:59AM and 1:00PM through 4:59PM:
* * * * 8:00-11:59,13:00-16:59
Every day from 1:00PM to 4:00PM:
* * * * 13:00-16:00
All day, every Saturday:
* * * 6 *
All day, every day, in February and March:
* 2,3 * * *
Every day in February and March, from noon to 3PM:
* 2,3 * * 12:00-15:00
...and so on.
In general, the module works as follows:
- When a user connects, the module looks for the user in the list of users.
- If the user is not found then access is granted.
- If the user is found, then the default rule is applied.
- Each rule in the rules list is evaluated.
- If the rule doesn't apply to the current time, then it is ignored.
- If the rule does apply to the current time, then it is applied.
- Each rule may reverse the outcome the previous rules.
- When all rules have been applied, the user will have been allowed or denied access.
Query Filtering
Query Filter modules enable the SQL Relay server programs to accept some queries, and filter out other queries, not passing them along to the database.
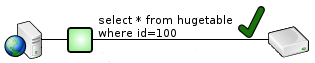

Query filters are implemented by loadable modules. The filters section of the configuration file indicates which filter modules to load and what parameters to use when executing them.
<?xml version="1.0"?> <instances> ... <instance ...> ... <filters> <filter module="regex" pattern=" [0-9]*=[0-9]*" errornumbrer="100" error="regex filter violation"/> </filters> ... </instance> ... </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
All filter modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All filter modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
All filter modules have an when attribute as well, which determines when the filter is applied. If set to "before" then the module is executed before any query translations are executed. If set to "after", or omitted, then the module is executed after all query translations have been executed. See Query Translations below for more information.
Filter modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
<?xml version="1.0"?> <instances> ... <instance ...> ... <filters> <filter module="regex" pattern=" [0-9]*=[0-9]*"/> <filter module="regex" pattern="^(create)"/> <filter module="regex" pattern="^(drop)"/> <filter module="string" pattern="hugetable" ignorecase="yes"/> <filter module="string" pattern="badschema" ignorecase="yes"/> </filters> ... </instance> ... </instances>
At startup, the SQL Relay server creates instances of the specified filter modules and initializes them. When a query is run, the server passes the query to each module, in the order that they were specified in the config file. If a module filters out the query, then it isn't passed along to the next module, nor is it sent to the database, and the client program is told that the query failed.
When using query filters, it is helpful to use the normalize query translation too:
<?xml version="1.0"?> <instances> ... <instance ...> ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> ... <filters> <filter module="regex" pattern=" [0-9]*=[0-9]*"/> </filters> ... </instance> ... </instances>
Pattern matching is substantially more reliable and efficient if the query has been normalized first. See Query Translations and the normalize translation below for more information.
Currently, the following filter modules are available in the standard SQL Relay distribution:
- patterns
- regex
- string
Custom modules may also be developed. For more information, please contact dev@firstworks.com.
patterns
The patterns module matches the query against a specified set of patterns. Each pattern may be a string, case-insensitive string, or regular expression. Each pattern may also be matched against the entire query, only the parts of the query that are outside of quotes, or only the parts of the query that are contained within quotes. If the query matches, then it is filtered out.
The list of patterns is given by a set of pattern child tags. Each pattern tag may contain the following attributes.
- pattern - Required. The pattern to match.
- type - Optional. Defaults to "string". Valid values are "string", "cistring" (case insensitive string), and "regex" (regular expression).
- scope - Optional. Defaults to "query". Valid values are "query" (attempt to match against the entire query), "outsidequotes" (only match parts of the query not surrounded by single-quotes), and "insidequotes" (only match parts of the query surrounded by single-quotes).
- errornumber - Optional. Defaults to 0. The error number to return to the client if the query matches this filter.
- error - Optional. Defaults to an empty string. The error string to return to the client if the query matches this filter.
For example, with the following configuration...
<?xml version="1.0"?> <instances> ... <instance ...> ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> ... <filters> <filter module="patterns"> <pattern type="regex" pattern="^(create)"/> <pattern type="regex" pattern="^(drop)"/> <pattern type="cistring" pattern="hugetable"/> <pattern type="string" pattern="badstring" scope="insidequotes"/> </filter> </filters> ... </instance> ... </instances>
These queries would be filtered out:
drop table mytable create table mytable (col1 int) select * from HugeTable select * from badstringtable where col1='badstring'
But these queries would not be:
insert into mytable values (1) select * from goodtable select * from badstringtable where col1='goodstring'
regex
The regex module matches the query against a specified regular expression pattern. If the query matches, then it is filtered out. This module is useful if you need to do a quick match, without the complexity of the patterns module.
In addition to the module attribute, each filter tag may contain the following attributes.
- pattern - Required. The pattern to match.
- errornumber - Optional. Defaults to 0. The error number to return to the client if the query matches this filter.
- error - Optional. Defaults to an empty string. The error string to return to the client if the query matches this filter.
For example, with the following configuration:
<?xml version="1.0"?> <instances> ... <instance ...> ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> ... <filters> <filter module="regex" pattern=" [0-9]*=[0-9]*"/> </filters> ... </instance> ... </instances>
This query would be filtered out:
select * from mytable where column1=1 and 1=1
But this query would not be:
select * from mytable where column1=1
string
The string module matches the query against a specified string pattern. If the query matches, then it is filtered out. This module is useful if you need to do a quick match without the complexity of regular expressions or of the patterns module.
In addition to the module attribute, each filter tag may contain the following attributes.
- pattern - Required. The pattern to match.
- ignorecase - Optional. Defaults to "no". If set to "yes" then the comparison is case insensitive.
- errornumber - Optional. Defaults to 0. The error number to return to the client if the query matches this filter.
- error - Optional. Defaults to an empty string. The error string to return to the client if the query matches this filter.
For example, with the following configuration:
<?xml version="1.0"?> <instances> ... <instance ...> ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> ... <filters> <filter module="string" pattern="hugetable" ignorecase="yes" errornumbrer="100" error="string filter violation"/> </filters> ... </instance> ... </instances>
This query would be filtered out:
select * from hugetable
But this query would not be:
select * from goodtable where column1=1
tag
The tag module matches queries in the same manner as the patterns module described above, and is configured similarly:
<?xml version="1.0"?> <instances> ... <instance ...> ... <moduledatas> <moduledata module="tag" id="tags"/> </moduledatas> ... <filters> <filter module="tag"> <pattern type="regex" pattern="^(create)" tag="create or drop query" moduledataid="tags"/> <pattern type="regex" pattern="^(drop)" tag="create or drop query" moduledataid="tags"/> <pattern type="cistring" pattern="hugetable" tag="hugetable query" moduledataid="tags"/> <pattern type="string" pattern="badstring" scope="insidequotes" tag="contains badstring" moduledataid="tags"/> </filter> </filters> ... </instance> ... </instances>
Note the moduledata tag defined prior to the filters tag. Moduledata modules basically allow one module to pass data to another. See Module Data below for more details. The tag filter module interoperates with the tag moduledata module and requires an instance of it to work.
In the tag module, if the query matches the pattern, then instead of filtering it out so that it isn't executed, the query is "tagged" with the value specified in the tag attribute in the instance of moduledata specified by the moduledataid attribute. Other modules (translation modules, for example) could then query the specified moduledata for the presence or absence of this value, and act accordingly.
Currently, no open source modules make use of the tag filter/moduledata module, however custom modules may be developed. For more information, please contact dev@firstworks.com.
Data Translation
SQL Relay offers features for parsing and translating queries, and translating result sets.
Query Parsing
Query parsing enables the SQL Relay server to create a DOM tree representing the query, which can be more easily processed than plain text by other modules.
Parsers are implemented as loadable modules. The parser section of the configuration file indicates which parser module to load and what parameters to configure it with.
<?xml version="1.0"?> <instances> <instance ...> ... <parser module="example" .../> ... </instance> </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
At startup, the SQL Relay server creates an instance of the specified parser modules and initializes it. When a query is run, the server passes the query to the parser, which parses it and makes the DOM tree representing the query available to other modules.
Currently, no open source parser modules are available, however custom modules may be developed. For more information, please contact dev@firstworks.com.
Query Translation
Query translation enables the SQL Relay server to modify queries before passing them to the database.
Query translation is implemented by loadable modules. The querytranslations section of the configuration file indicates which query translation modules to load and what parameters to use when executing them.
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> ... </instance> ... </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
All query translation modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All query translation modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Query translation modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
At startup, the SQL Relay server creates instances of the specified query translations modules and initializes them. When a query is run, the server passes the query to each module, in the order that they were specified in the config file. If a module modifies the query, then that modified query is passed on to the next module.
Currently, the following query translation modules are available in the standard SQL Relay distribution:
- normalize
- patterns
Custom modules may also be developed. For more information, please contact dev@firstworks.com.
normalize
The normalize module performs the following operations on a query:
- Removes comments.
- Converts all white-space characters to spaces, outside of quoted strings.
- Converts multiple spaces into a single space, outside of quoted strings.
- Removes whitespace from around operators.
- Converts static concatenations to equivalent strings. Eg. converts 'he' || 'll' || 'o' to 'hello'.
- Optionally converts the query to lower or upper case as specified by parameters described below.
- Optionally converts comma-separated decimals to dot-separated decimals.
- Optionally removes double-quotes around database object names.
For example, the following query:
sElEcT *, 'He' || 'Ll' || 'o' from myTABLE where myTaBLe.CoLuMn1 = myTablE.ColuMN2 / 2
Would be translated to:
select *, 'HeLlo' from mytable where mytable.column1 = mytable.column2/2
Normalizing a query is useful when also using query filtering as it simplifies the patterns that have to be searched for.
The following attributes are currently supported:
- foreigndecimals - "yes" or "no". Defaults to "no".
- SQL requires dots for decimal separators. However, some internationalized apps are not well behaved and build queries with decimals that use commas for decimal separators. This attribute instructs the module to try to identify comma-separated decimals and replace the commas with dots.
- This can be tricky, especially with decimals in parentheses, which can be misinterpreted as parameters. To help manage this, a space before a set of comma-separated numbers is interpreted as a delimiter, and no number may have more than 1 decimal separator.
- For example:
- (111,222, 333,444) is interpreted as having 2 decimals: 111.222 and 333.444
- (111, 222, 333,444) is interpreted as having 2 integers and 1 decimal: 111 and 222 and 333.444
- (111,222, 333,444,555) is interpreted as having 2 decimals and 1 integer: 111.222 and 333.444 and 555
- (111,222) is interpreted as 2 integers: 111 and 222
- ( 111,222) is interpreted as 1 decimal: 111.222
- etc.
- convertcase - "upper", "lower", or "no". Defaults to "lower".
- If set to "upper" or "lower" then the entire query is converted to the specified case, except for strings surrounded by single or double quotes.
- If set to "no" then no case conversion is done.
- If omitted then the value defaults to "lower".
- convertcasedoublequoted - "upper", "lower", "yes", or "no". Defaults to "no".
- If set to "upper" or "lower" then values enclosed in double-quotes are converted to the specified case. Double-quotes usually surround the names of database objects such as table, index, or column names to indicate that they should be interpreted in a case-sensitive manner. So, effectively, setting this to "yes" forces the case of the quoted object names in the query.
- Some databases (eg. Oracle) default object names to upper case when creating the object, if the object names are unquoted in the create statement.
- Eg. 'create table exampletable (col1 int)' creates a table named EXAMPLETABLE with a column named COL1.
- Some databases (eg. PostgreSQL, MySQL/MariaDB, others) default object names to the specified case when creating the object, if the object names are unquoted in the create statement.
- Eg. 'create table exampletable (col1 int)' creates a table named exampletable with a column named col1.
- This can be useful when converting an app from one type of database to the other if the app's queries contain quoted object names.
- If set to "yes" then values enclosed in double-quotes are converted to the case specified by the convertcase attribute.
- If set to "no" then no case conversion is done.
- If omitted then the value defaults to "no".
- convertcasebackquoted - "upper", "lower", "yes", or "no". Defaults to "no".
- If set to "upper" or "lower" then values enclosed in back-quotes are converted to the specified case. In some database (MySQL/MariaDB) back-quotes can be used to surround the names of database objects such as table, index, or column names to indicate that they should be interpreted in a case-sensitive manner. So, effectively, setting this to "yes" forces the case of the quoted object names in the query.
- Some databases (eg. Oracle) default object names to upper case when creating the object, if the object names are unquoted in the create statement.
- Eg. 'create table exampletable (col1 int)' creates a table named EXAMPLETABLE with a column named COL1.
- Some databases (eg. PostgreSQL, MySQL/MariaDB, others) default object names to the specified case when creating the object, if the object names are unquoted in the create statement.
- Eg. 'create table exampletable (col1 int)' creates a table named exampletable with a column named col1.
- This can be useful when converting an app from one type of database to the other if the app's queries contain quoted object names.
- If set to "yes" then values enclosed in back-quotes are converted to the case specified by the convertcase attribute.
- If set to "no" then no case conversion is done.
- If omitted then the value defaults to "no".
- removedoublequotes - "yes" or "no". Defaults to "no".
- If set to "yes" then double-quotes are removed, except for escaped double quotes. Double-quotes usually surround the names of database objects such as table, index, or column names to indicate that they should be interpreted in a case-sensitive manner. So, effectively, setting this to "yes" causes the database to interpret the object names case-insensitively.
- Some databases (eg. Oracle) default object names to upper case when creating the object, if the object names are unquoted in the create statement.
- Eg. 'create table exampletable (col1 int)' creates a table named EXAMPLETABLE with a column named COL1.
- Some databases (eg. PostgreSQL, MySQL/MariaDB, others) default object names to the specified case when creating the object, if the object names are unquoted in the create statement.
- Eg. 'create table exampletable (col1 int)' creates a table named exampletable with a column named col1.
- This can be useful when converting an app from one type of database to the other if the app's queries contain quoted object names.
- If set to "no" then double-quotes are not removed.
- If omitted then the value defaults to "no".
- removebackquotes - "yes" or "no". Defaults to "no".
- If set to "yes" then back-quotes are removed, except for escaped back quotes. In some databases (MySQL/MariaDB) back-quotes can be used to surround the names of database objects such as table, index, or column names to indicate that they should be interpreted in a case-sensitive manner. So, effectively, setting this to "yes" causes the database to interpret the object names case-insensitively.
- Some databases (eg. Oracle) default object names to upper case when creating the object, if the object names are unquoted in the create statement.
- Eg. 'create table exampletable (col1 int)' creates a table named EXAMPLETABLE with a column named COL1.
- Some databases (eg. PostgreSQL, MySQL/MariaDB, others) default object names to the specified case when creating the object, if the object names are unquoted in the create statement.
- Eg. 'create table exampletable (col1 int)' creates a table named exampletable with a column named col1.
- This can be useful when converting an app from one type of database to the other if the app's queries contain quoted object names.
- If set to "no" then back-quotes are not removed.
- If omitted then the value defaults to "no".
- slashescape - "yes" or "no". Defaults to "yes".
- Most databases support double-escaped quotes. For example, if a quoted string needs to contains a quote, then that would be expressed like: 'I said ''hello'' to her.'
- Some databases support slash-escaped quotes. For example, if a quoted string needs to contains a quote, then that would be expressed like: 'I said \'hello\' to her.'
- By default, the normalize query translation converts slash-escaped single, double, and back-quotes to double-escaped single, double, and back-quotes.
- If slashescape is set to "no" then the slash will be ignored as an escape character, and the quote (or double/back quote) and slash will be interpreted literally, potentially affecting case conversion and quote removal.
- doubleescape - "yes" or "no". Defaults to "yes".
- Most databases support double-escaped quotes. For example, if a quoted string needs to contains a quote, then that would be expressed like: 'I said ''hello'' to her.'
- By default, the normalize query translation interprets double-escaped single, double, and back-quotes in this manner.
- If doubleescape is set to "no" then all quotes, double-quotes, and back-quotes will be interpreted literally, potentially affecting case conversion and quote removal.
patterns
The patterns module enables you to match the entire query, or parts of it, against a pattern, and then replace the matching part.
The module is highly configurable, and capable of doing some fairly complex substitutions. For example:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="normalize"/> <querytranslation module="patterns"> <pattern type="string" from="old_tablename" to="new_tablename" scope="outsidequotes"/> <pattern type="string" from="David" to="Dave" scope="insidequotes"/> <pattern type="cistring" from="Johnathan" to="John" scope="insidequotes"/> <pattern type="regex" from="(Dan|Danny)" to="Daniel" scope="insidequotes"/> <pattern type="regex" from="(Rich|Richie)" to="Richard" scope="insidequotes" global="no"/> <pattern type="regex" from="^show tables$" to="select * from user_tables"/> </querytranslation> </querytranslations> ... </instance> ... </instances>
In this example, several pattern query translations are defined, instructing the module to:
- Convert old_tablename to new_tablename, but only outside of quoted strings.
- Convert David to Dave, but only inside of quoted strings.
- Convert Johnathan to John, but only inside of quoted strings, and using case-insensitive matching.
- Convert Dan or Danny to Daniel, but only inside of quoted strings.
- Convert only the first instance of Rich or Richie to Richard, and only inside of quoted strings.
- Convert the entire query show tables to the entire query select * from user_tables.
This example illustrates the use of several attributes of the pattern tag:
- type - The type of matching to do. Options include:
- string - basic string matching - the default
- cistring - case-insensitive string matching
- regex - regular-expression matching
- from - The pattern to match.
- to - The string to convert matching parts of the query to.
- scope - Where to match and translate. Options include:
- anywhere - anywhere in the query - the default
- outsidequotes - only outside of quoted strings
- insidequotes - only inside of quoted strings
- global - Only valid when type="regex". Options include:
- yes - find all matches - the default
- no - only find the first match
Note that in this example, the normalize query translation is loaded prior to the patterns query translation. Pattern matching is substantially more reliable and efficient if the query has been normalized first. See the normalize query translation for more information.
Another powerful feature of the patterns query translation module is nested matching:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="normalize"/> <querytranslation module="patterns"> <pattern type="regex" match="^create table .*"> <pattern type="string" from=" tinytext," to=" varchar2(254),"/> <pattern type="string" from=" mediumtext," to=" varchar2(1023),"/> <pattern type="string" from=" longtext," to=" clob,"/> </pattern> <pattern type="regex" match="^select .*,oldvalue,newvalue,.* from ticket_change .* union .*"> <pattern type="string" from=",oldvalue,newvalue," to=",to_char(oldvalue),to_char(newvalue),"/> </pattern> </querytranslation> </querytranslations> ... </instance> ... </instances>
In this example...
The first pattern query translation replaces:
- the tinytext column type with varchar2(254)
- the mediumtext column type with varchar2(1023)
- the longtext column type with clob
But the replacements are only done in create table queries.
It's unlikely that those patterns would show up in other queries, but not impossible. Also, the query translation is made more efficient by the initial match, as it will bail immediately if the query is something other than a create table, rather than having to scan the entire rest of the query.
The second pattern query translation basically wraps oldvalue and newvalue with to_char(), but only in a very specific query. This is a good example of how the patterns query translation can help run an app written for one type of database against a different type of database. One-off query translations are often necessary in these cases.
Note that in these examples, the outer pattern tags have a match attribute rather than from/to attributes. When doing nested matching, outer tags use the match attribute to grab pieces of the query, and pass them down to nested tags.
The type, scope, and global attributes are valid for outer pattern tags, but the from and to attributes are ignored in any pattern tag with a match attribute.
Note also that in these examples, the nested pattern tags use type="string", but type="regex" and type="cistring" are supported, as is the global attribute for type="regex". However, the scope attribute is only valid at the top level and is ignored in nested pattern tags.
Though more than 2 levels is rarely necessary, any level of nesting is supported:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="normalize"/> <querytranslation module="patterns"> <pattern type="regex" match="...pattern to match in query..."> <pattern type="regex" match="...pattern to match in matching pieces of query..."> <pattern type="regex" match="...pattern to match in those pieces..."> <pattern type="regex" match="...and so on..."> <pattern type="string" from="...from pattern..." to="...to pattern..."/> </pattern> </pattern> </pattern> </pattern> </querytranslation> </querytranslations> ... </instance> ... </instances>
Bind Variable Translation
Bind variable translation enables the SQL Relay server to modify bind variables before passing them to the database. Bind variable names or values may be modified. Variables may also be added or deleted. Bind variable translation is most often used in conjunction with query translation.
Bind variable translation is implemented by loadable modules. The bindvariabletranslations section of the configuration file indicates which translation modules to load and what parameters to use when executing them.
<?xml version="1.0"?> <instances> <instance ...> ... <bindvariabletranslations> <bindvariabletranslation module="example" .../> </bindvariabletranslations> ... </instance> </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
All bind variable translation modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All bind variable translation modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Bind variable translation modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
At startup, the SQL Relay server creates instances of the specified bind variable translations modules and initializes them. When a query is run, the server passes the bind variables to each module, in the order that they were specified in the config file. If a module modifies a bind variable, then that modified variable is passed on to the next module.
Currently, no open source bind variable translation modules are available, however custom modules may be developed. For more information, please contact dev@firstworks.com.
Result Set Header Translation
Result set header translation enables the SQL Relay server to modify column information in the result set before returning it to the client. Result set header translation is most often used in conjunction with result set translation.
Result set header translation is implemented by loadable modules. The resultsetheadertranslations section of the configuration file indicates which translation modules to load and what parameters to use when executing them.
<?xml version="1.0"?> <instances> <instance ...> ... <resultsetheadertranslations> <resultsetheadertranslation module="example" .../> </resultsetheadertranslations> ... </instance> </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
All result set header translation modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All result set header translation modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Result set header translation modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
At startup, the SQL Relay server creates instances of the specified result set header translations modules and initializes them. When a query is run, the server passes the result set header to each module, in the order that they were specified in the config file. If a module modifies the result set header, then that modified header is passed on to the next module.
Currently, no open source result set header translation modules are available, however custom modules may be developed. For more information, please contact dev@firstworks.com.
Result Set Translation
Result set translation enables the SQL Relay server to modify fields in the result set before returning the field to the client.
Result set translation is implemented by loadable modules. The resultsettranslations section of the configuration file indicates which result set translation modules to load and what parameters to use when executing them.
<?xml version="1.0"?> <instances> <instance ...> ... <resultsettranslations> <resultsettranslation module="reformatdatetime" datetimeformat="MM/DD/YYYY HH24:MI:SS" dateformat="MM/DD/YYYY" timeformat="HH24:MI:SS" dateddmm="yes" ignorenondatetime="yes"/> </resultsettranslations> ... </instance> </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
All result set translation modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All result set translation modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Result set translation modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
At startup, the SQL Relay server creates instances of the specified result set translation modules and initializes them. As each field of the result set is returned, the server passes the field to each module, in the order that they were specified in the config file. If a module modifies a field, then that modified field is passed on to the next module.
Currently, the following result set translation module is available in the standard SQL Relay distribution:
- reformatdatetime
Custom modules may also be developed. For more information, please contact dev@firstworks.com.
reformatdatetime
The reformatdatetime module examines the field, decides if it's a date/time field, and if so, reformats it based on the given attributes.
The following attributes are currently supported:
- datetimeformat - Specifies the format to convert date/time fields to. May be any combination of the following format characters. Non-format characters will be inserted as-is.
- DD - 2 digit day, left padded with 0
- D - 1 or 2 digit day, not left padded with 0
- MM - 2 digit month, left padded with 0
- MON - uppercase, 3-character month abbreviation
- Month - mixed-case full name of the month
- YYYY - 4 digit year, left padded with 0
- YY - 2 digit year, left padded with 0
- HH24 - 2 digit hour, in 24-hour format, left padded with 0
- HH - 2 digit hour, in 12-hour format, left padded with 0
- MI - 2 digit minute, left padded with 0
- SS - 2 digit second, left padded with 0
- FFFFFF - 6 digit fractional second, left padded with 0
- FFFFF - 5 digit fractional second, left padded with 0
- FFFF - 4 digit fractional second, left padded with 0
- FFF - 3 digit fractional second, left padded with 0
- FF - 2 digit fractional second, left padded with 0
- F - 1 digit fractional second
- AM - AM or PM
- dateformat - Similar to datetimeformat but if a date without the time component is detected, the supplied format will be used instead of the format supplied in the datetimeformat attribute. Defaults to whatever value was supplied in the datetimeformat attribute.
- timeformat - Similar to datetimeformat but if a time without the date component is detected, the supplied format will be used instead of the format supplied in the datetimeformat attribute. Defaults to whatever value was supplied in the datetimeformat attribute.
- dateddmm - If set to "yes" then dates are assumed to be in the DD-MM-YYYY format (with days leading), as opposed to MM-DD-YYYY format (with months leading). This is important for interpreting dates like 03-04-2000. If this attribute is set to "yes" then it would be interprted as March 4th rather than April 3rd.
- dateyyddmm - If set to "yes" then dates are assumed to be in the YYYY-DD-MM format (with days leading), as opposed to YYYY-MM-DD-YYYY (with months leading). This is important for interpreting dates like 2000-03-04. If this attribute is set to "yes" then it would be interprted as March 4th rather than April 3rd.
- datedelimiters - Determining whether the field is a date/time or not can be tricky. Different cultures and systems delimit dates with different characteres, including slashes, dashes, colons and periods. This attribute enables you to specify which of these to pay attention to. For example, if your database contains both slash-delimited and dash-delimited dates, but also contains dot-delimited data that could be misinterpreted as a date, then you'd want to set this to "/-". Defaults to "/-:." Characters other than slash, dash, colon and dot are ignored.
- ignorenondatetime - If this attribute is set to "yes" then only fields with date/time datatypes will be examined. Char, and varchar fields, for example, will be ignored. By default, all fields are examined and heuristics are used to determine whether the field contains a date/time.
For example, the following configuration:
<?xml version="1.0"?> <instances> <instance ...> ... <resultsettranslations> <resultsettranslation module="reformatdatetime" datetimeformat="MM/DD/YYYY HH24:MI:SS" dateformat="MM/DD/YYYY" timeformat="HH24:MI:SS" dateddmm="yes" ignorenondatetime="yes"/> </resultsettranslations> ... </instance> </instances>
Would translate the following date/time field:
Jul 10 2015 05:17:55:717PM
Into:
07/10/2015 17:18:55
Note that dateddmm and dateyyddmm should usually be set to the same thing. There are very specific cases where these two attributes need to be set differently from one another. You'll know if you need to.
Note also that date/time translation in general is especially problematic with MS SQL Server. See the FAQ for more info.
Result Set Row Translation
Result set row translation is similar to result set translation, except that an entire row is buffered and sent to the translation module, instead of fields being sent to the module one-at-a-time.
This is useful if the value of one field needs to change based on the value of another field. It also tends to perform better than translating one field at a time.
<?xml version="1.0"?> <instances> <instance ...> ... <resultsetrowtranslations> <resultsetrowtranslation module="example" .../> </resultsetrowtranslations> ... </instance> </instances>
Currently, no open source result set row translation modules are available, however custom modules may be developed. For more information, please contact dev@firstworks.com.
Result Set Row Block Translation
Result set row block translation is similar to result set translation, except that blocks of rows are buffered and sent to the translation module, instead of individual rows or fields being sent to the module one-at-a-time.
This is useful for the same reasons as result set row translation, and tends to be the highest performing option for translating result sets, but the modules tend to be complex.
<?xml version="1.0"?> <instances> <instance ...> ... <resultsetrowblocktranslations rowblockcount="100"> <resultsetrowblocktranslation module="example" .../> </resultsetrowblocktranslations> ... </instance> </instances>
Currently, no open source result set row block translation modules are available, however custom modules may be developed. For more information, please contact dev@firstworks.com.
Error Translation
Error translation enables the SQL Relay server to modify errors before passing them back to the client.
Error translation is implemented by loadable modules. The errortranslations section of the configuration file indicates which error translation modules to load and what parameters to use when executing them.
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="renumber"> <!-- table already exists --> <renumber from="955" to="1050"/> <!-- table doesn't exist --> <renumber from="942" to="1051"/> </querytranslation> </querytranslations> ... </instance> ... </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
All error translation modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All error translation modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Error translation modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
At startup, the SQL Relay server creates instances of the specified error translations modules and initializes them. When a query is run, the server passes the query to each module, in the order that they were specified in the config file. If a module modifies the query, then that modified query is passed on to the next module.
Currently, the following error translation modules are available in the standard SQL Relay distribution:
- renumber
- patterns
Custom modules may also be developed. For more information, please contact dev@firstworks.com.
renumber
The renumber module enables you to replace one error number with another.
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="renumber"> <!-- table already exists --> <renumber from="955" to="1050"/> <!-- table doesn't exist --> <renumber from="942" to="1051"/> </querytranslation> </querytranslations> ... </instance> ... </instances>
In this example:
- Oracle error number 955 (ORA-00955: name is already used by an existing object) is replaced with MySQL error number 1050 (Table already exists)
- Oracle error number 942 (ORA-00942: table or view does not exist) is replaced with MySQL error number 1051 (Unknown table)
patterns
The patterns module enables you to match the entire error string, or parts of it, against a pattern, and then replace the matching part.
The module is highly configurable, and capable of doing some fairly complex substitutions. For example:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <errortranslations> <errortranslation module="patterns"> <pattern type="string" from="ORA-00955: name is already in use by an existing object" to="Table already exists" scope="outsidequotes"/> <pattern type="string" from="ORA-00942: table or view does not exist" to="Unknown table" scope="outsidequotes"/> <pattern type="string" from="old_tablename" to="new_tablename" scope="insidequotes"/> <pattern type="cistring" from="Old_Tablename" to="new_tablename" scope="insidequotes"/> <pattern type="regex" from="(ORA-00955:|ORA-00942:)" to="ORA-99999:" scope="outsidequotes"/> <pattern type="regex" from="ORA-" to="ora-" scope="outsidequotes" global="no"/> <pattern type="regex" from="^ORA-" to="ora-"/> </errortranslation> </errortranslations> ... </instance> ... </instances>
In this example, several pattern-translations are defined, instructing the module to:
- Convert the error string "ORA-00955: name is already in use by an existing object" to "Table already exists".
- Convert the error string "ORA-00942: table or view does not exist" to "Unknown table".
- Convert old_tablename to new_tablename, but only inside of quoted strings. (Some errors containg quoted table names)
- Convert Old_Tablename to new_tablename, but only inside of quoted strings, and using case-insensitive matching. (Some errors contain quoted table names)
- Convert ORA-00955: or ORA-00942: to ORA-99999:, but only outside of quoted strings.
- Convert only the first instance of ORA- to ora-, but only outside of quoted strings.
- Convert ORA- to ora- if the error string begins with ORA-.
( NOTE: Some of the configurations above are nonsensical or redundant, but are included for the sake of illustration.)
This example illustrates the use of several attributes of the pattern tag:
- type - The type of matching to do. Options include:
- string - basic string matching - the default
- cistring - case-insensitive string matching
- regex - regular-expression matching
- from - The pattern to match.
- to - The string to convert matching parts of the query to.
- scope - Where to match and translate. Options include:
- anywhere - anywhere in the query - the default
- outsidequotes - only outside of quoted strings
- insidequotes - only inside of quoted strings
- global - Only valid when type="regex". Options include:
- yes - find all matches - the default
- no - only find the first match
Another powerful feature of the patterns translation module is nested matching:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <errortranslations> <errortranslation module="patterns"> <pattern type="regex" match="^ORA-00955:.*"> <pattern type="string" from="name is already in use by an existing object" to="Table already exists"/> </pattern> <pattern type="regex" match="^ORA-00942:.*"> <pattern type="string" from="table or view does not exist" to="Unknown table"/> </pattern> </errortranslation> </errortranslations> ... </instance> ... </instances>
In this example...
The first pattern-translation replaces "name is already in use by an existing object" with "Table already exists" but onle when the error begins with "ORA-00955:", resulting in: "ORA-00955: Table already exists".
The second pattern-translation replaces "table or view does not exist" with "Unknown table" but onle when the error begins with "ORA-00942:", resulting in "ORA-00942: Unknown table".
( NOTE: There are easier ways to perform this replacement, but this way is included for the sake of illustration.)
Note that in these examples, the outer pattern tags have a match attribute rather than from/to attributes. When doing nested matching, outer tags use the match attribute to grab pieces of the query, and pass them down to nested tags.
The type, scope, and global attributes are valid for outer pattern tags, but the from and to attributes are ignored in any pattern tag with a match attribute.
Note also that in these examples, the nested pattern tags use type="string", but type="regex" and type="cistring" are supported, as is the global attribute for type="regex". However, the scope attribute is only valid at the top level and is ignored in nested pattern tags.
Though more than 2 levels is rarely necessary, any level of nesting is supported:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <errortranslations> <errortranslation module="patterns"> <pattern type="regex" match="...pattern to match in error..."> <pattern type="regex" match="...pattern to match in matching pieces of error..."> <pattern type="regex" match="...pattern to match in those pieces..."> <pattern type="regex" match="...and so on..."> <pattern type="string" from="...from pattern..." to="...to pattern..."/> </pattern> </pattern> </pattern> </pattern> </errortranslation> </errortranslations> ... </instance> ... </instances>
Module Data
Moduledata modules allow a developer to pass data between modules. For example, a query translation module could set a value that a result set translation module could later read.
<?xml version="1.0"?> <instances> <instance ...> ... <moduledatas> <moduledata module="tag" id="tags"/> </moduledatas> ... </instance> </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
Module data modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
At startup, the SQL Relay server creates one instance of the moduledata specified in each moduledata tag. Each of these tags must specify an id attribute. This id can be used by other modules to access this instance of moduledata. If more than one instance of the same kind of moduledata is required, then multiple moduledata tags may be specified with the same module attribute and different id attributes.
Currently, the only open source moduledata module available is:
- tag
The tag module works as specified above in the documentation for the tag filter.
Custom modules may also be developed. For more information, please contact dev@firstworks.com.
Query Directives
Query directives enable an app to give the SQL Relay server special per-query instructions in the comments preceeding the query.
-- a directive -- another directive: with a parameter -- yet another directive select * from exampletable
Query directives are implemented by loadable modules. The directives section of the configuration file indicates which directive modules to load and what parameters to use when executing them.
<?xml version="1.0"?>
<instances>
<instance ...>
...
<directives>
<directive module="custom_wf"/>
</directives>
...
</instance>
</instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
All directive modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All directive modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Directive modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
At startup, the SQL Relay server creates instances of the specified directive modules and initializes them. When a query is run, the server passes the query to each module, in the order that they were specified in the config file.
Currently, the following directive modules are available in the standard SQL Relay distribution:
- custom_wf
- singlestep
Custom modules may also be developed. For more information, please contact dev@firstworks.com.
custom_wf
<?xml version="1.0"?>
<instances>
<instance ...>
...
<directives>
<directive module="custom_wf"/>
</directives>
...
</instance>
</instances>
The custom_wf module examines the comments preceeding the query and looks for one or more of the following directives:
- sqlexecdirect
- sqlprepare
- querytimeout
sqlexecdirect
The sqlexecdirect directive tells SQL Relay to execute the query in a single step, rather than using the standard prepare/execute process. This is useful for overriding the executedirect=no connection string option (the default) on a case-by-case basis.
-- sqlexecdirect select * from exampletable
Note that (currently) the only database back-end that supports executedirect is ODBC, and the only ODBC driver where it is known to improve performance is the MS SQL Server driver. In that environment, this directive can yield a noticeable performance improvement for queries without bind variables, and which won't be reexecuted immediately.
sqlprepare
The sqlprepare directive tells SQL Relay to prepare/execute the query in a two-step step process, rather than executing the query in a single step. This is useful for overriding the executedirect=yes connection string option on a case-by-case basis.
-- sqlprepare select * from exampletable
Note that (currently) the only database back-end that supports direct execution is ODBC, and the only ODBC driver where it is known to improve performance is the MS SQL Server driver. In that environment, the executedirect=yes option can yield a noticeable performance improvement for queries without bind variables, and which won't be reexecuted immediately. If this is the case for most of your queries, then it makes sense to set executedirect=yes and override it using this directive as needed.
querytimeout
The querytimeout directive sets a timeout (in seconds) for the query. The following example sets a 60 second timeout.
-- querytimeout:60 select * from exampletable
Note that this directive takes a colon-delimited parameter, the number of seconds. Setting a timeout of 0 seconds (or removing the parameter) disables the timeout.
Note that (currently) the only database back-end that supports query timeouts is ODBC. It is known to work with the MS SQL Server driver, though it likely works with some other ODBC drivers as well.
singlestep
<?xml version="1.0"?>
<instances>
<instance ...>
...
<directives>
<directive module="singlestep"/>
</directives>
...
</instance>
</instances>
The singlestep module only works when using a PostgreSQL database. Attempts to use it with a different database will have no effect.
When using a PostgreSQL database, the connect string option fetchatonce can be set to 0 or 1. When set to 0, the SQL Relay server fetches and buffers all rows of the result set from the database before returning any to the SQL Relay client. When set to 1, the SQL Relay server "single-steps" through the rows of the result set, fetching one row at a time from the database, and sending each row back to the SQL Relay client as it is fetched.
Using fetchatonce=0 can cause the SQL Relay serve to consume large amounts of memory when a query returns a large number of rows. On the other hand, when using fetchatonce=1, due to the quirky way that PostgreSQL implements fetching one row at a time, if you run a set of nested queries, rows will be truncated in the outer query, if the client uses a non-zero result set buffer size. See the faq for more details.
The singlestep module allows you to configure the instance one way, but override that configuration on a query-by-query basis.
The module examines the comments preceeding the query and looks for one or more of the following directives:
- singlestep=on
- singlestep=off
singlestep=on
If the singlestep=on directive is used, the SQL Relay Server "single-steps" through the rows of the result set of the associated query, fetching one row at a time from the database and sending each row back to the SQL Reay client as it is fetched.
-- singlestep=on select * from largetable
singlestep=off
If singlestep=off is set, then the SQL Relay Server will fetch and buffer all rows of the result set of the associated query before returning any to the SQL Relay client.
-- singlestep=off select * from smalltable
Query and Session Routing
Query routing enables the SQL Relay server to send one set of queries to one database, another set of queries to another, another set of queries to another, and so on.
Session routing sends entire sessions to one database or another; by user, by intercepting "use database" queries, by client ip address, or by other criteria.
To route queries or sessions, one instance of SQL Relay must be configured as a router to route queries to other instances of SQL Relay which are configured normally.
A typical use case is to configure one instance of SQL Relay to maintain connections to a master database and another instance of SQL Relay to maintain connections to a pool of slaves, then set up a third instance of SQL Relay to route queries to the other 2 instances.
This is such a common case, that it is also described above in it's own section: Master-Slave Query Routing.
There are other possiblities as well though.
The actual routing itself is implemented by loadable modules. The routers section of the configuration file indicates which router modules to load and what parameters to use when executing them.
<?xml version="1.0"?>
<instances>
<instance ... dbase="router" ...>
...
<routers>
<router module="regex" connectionid="master">
<pattern pattern="^drop "/>
<pattern pattern="^create "/>
<pattern pattern="^insert "/>
<pattern pattern="^update "/>
<pattern pattern="^delete "/>
</router>
<router module="regex" connectionid="slave">
<pattern pattern=".*"/>
</router>
</routers>
<connections>
<connection connectionid="master" string="..."/>
<connection connectionid="slave" string="..."/>
</connections>
...
</instance>
</instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these elements are interpreted is module-specific.
All router modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All router modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Router modules can be "stacked". Multiple modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
In fact, the example above shows a stacked configuration. The first instance of the router module sends DDL/DML queries to a "master" database and the second instance of the router module sends all other queries to a "slave" database.
At startup, the SQL Relay server creates instances of the specified router modules and initializes them. When the client sends a query to the SQL Relay server, the server consults each router module, in the order that they were specified in the config file. Each module applies its routing rules to determine which connection to run the query on. If a module returns a connection then the remaining modules are ignored. If the query makes it through all modules without being routed to a particular connection, then the query is ignored.
Currently, the following router modules are available in the standard SQL Relay distribution:
Custom modules may also be developed. For more information, please contact dev@firstworks.com.
regex
The regex module routes queries by matching them against regular expressions.
A classic Master-Slave Query Routing configuration follows.
<?xml version="1.0"?>
<instances>
<!-- This instance maintains connections to the "master" MySQL database
on the masterdb machine. This instance only listens on the
unix socket /tmp/master.socket and thus cannot be connected to
by clients from another machine. -->
<instance id="master" socket="/tmp/master.socket" dbase="mysql">
<connections>
<connection string="user=masteruser;password=masterpassword;host=masterdb;db=master;"/>
</connections>
</instance>
<!-- This instance maintains connections to 4 "slave" MySQL databases
on 4 slave machines. This instance only listens on the unix
socket /tmp/slave.socket and thus cannot be connected to by
clients from another machine. -->
<instance id="slave" socket="/tmp/slave.socket" dbase="mysql">
<connections>
<connection string="user=slaveuser;password=slavepassword;host=slavedb1;db=slave;"/>
<connection string="user=slaveuser;password=slavepassword;host=slavedb2;db=slave;"/>
<connection string="user=slaveuser;password=slavepassword;host=slavedb3;db=slave;"/>
<connection string="user=slaveuser;password=slavepassword;host=slavedb3;db=slave;"/>
</connections>
</instance>
<!-- This instance sends DML (insert,update,delete) and
DDL (create/delete) queries to the "master" SQL Relay instance
which, in turn, sends them to the "master" database.
This instance sends any other queries to the "slave" SQL Relay
instance which, in turn, distributes them over the "slave"
databases. -->
<instance id="router" dbase="router">
<auths>
<auth module="sqlrclient_userlist">
<user user="routeruser" password="routerpassword"/>
</auth>
</auths>
<routers>
<!-- send all DML/DDL queries to "master" -->
<router module="regex" connectionid="master">
<pattern pattern="^drop "/>
<pattern pattern="^create "/>
<pattern pattern="^insert "/>
<pattern pattern="^update "/>
<pattern pattern="^delete "/>
</router>
<!-- send all other queries to "slave" -->
<router module="regex" connectionid="slave">
<pattern pattern=".*"/>
</router>
</routers>
<connections>
<connection connectionid="master" string="socket=/tmp/master.socket;user=masteruser;password=masterpassword"/>
<connection connectionid="slave" string="socket=/tmp/slave.socket;user=slaveuser;password=slavepassword"/>
</connections>
</instance>
</instances>
In this example, 3 SQL Relay instances are defined:
- one to maintain connections to the master database
- one to maintain connections to a pool of slave databases
- one to route queries to the other two instances
In this configuration, DDL/DML queries are routed to the connectionid "master", and all other queries are routed to the connectionid "slave".
The string attribute in each connection tag provides the parameters necessary to connect to the other instances. Valid attributes include:
- host - the host name or IP address of the SQL Relay instance
- port - the port of the SQL Relay instance
- socket - the socket of the SQL Relay instance, if it is running locally
- user - the user to use when connecting to the SQL Relay instance as
- password - the password to use when connecting to the SQL Relay instance
- fetchatonce - the number of rows to fetch at a time (defaults to 10, 0 means fetch the entire result set)
Note the use of a notification module to notify dba@firstworks.com if an integrity_violation event occurs. SQL Relay must maintain parallel transactions on all databases that a query may be routed to. An integrity violation occurs when a transaction control query (begin, commit, rollback, autocommit on, or autocommit off) succeeds on some of the back-ends but fails on others. See Notifications for information about notification modules.
Master-slave routing isn't all that the regex module can do though.
In the example below, we provide a single point of access to MySQL/MariaDB and PostgreSQL databases.
<?xml version="1.0"?> <instances> <!-- This instance maintains connections to a MySQL database --> <instance id="mysqldb" dbase="mysql"> <listener> <listener port="" socket="/tmp/mysqldb.socket"/> </listener> <connections> <connection string="user=mysqldbuser;password=mysqldbpassword;host=mysqldb;db=mysqldb;"/> </connections> </instance> <!-- This instance maintains connections to a PostgreSQL database --> <instance id="postgresqldb" dbase="postgresql"> <listeners> <listener port="" socket="/tmp/postgresqldb.socket"/> </listeners> <connections> <connection string="user=postgresqldbuser;password=postgresqldbpassword;host=postgresqldb;db=postgresqldb;"/> </connections> </instance> <!-- This instance sends queries containing "mysqldb." to the mysql database and "postgresqldb." to the postgresql database --> <instance id="router" dbase="router"> <auths> <auth module="sqlrclient_userlist"> <user user="routeruser" password="routerpassword"/> </auth> </auths> <routers> <!-- send all mysqldb queries to "mysqldb" --> <router module="regex" connectionid="mysqldb"> <pattern pattern="mysqldb\."/> </router> <!-- send all postgresqldb queries to "postgresqldb" --> <router module="regex" connectionid="postgresqldb"> <pattern pattern="postgresqldb\."/> </router> </routers> <connections> <connection connectionid="mysqldb" string="socket=/tmp/mysqldb.socket;user=mysqldbuser;password=mysqldbpassword"/> <connection connectionid="postgresqldb" string="socket=/tmp/postgresqldb.socket;user=postgresqldbuser;password=postgresqldbpassword"/> </connections> <notifications> <notification module="events"> <events> <event event="integrity_violation"/> </events> <recipients> <recipient address="dba@firstworks.com"/> </recipients> </notification> </notifications> </instance> </instances>
In this configuration, all queries containing "mysqldb." are sent to the connectionid "mysqldb" and all queries containing "postgresqldb." are sent to the connectionid "postgresqldb".
As above, the string attribute in each connection tag provides the parameters necessary to connect to the other instances.
Note the use of a notification module, as above.
userlist
The userlist module routes queries by matching the user that ran the query against a list of users.
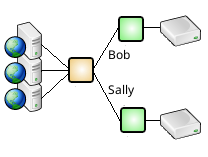
An example configuration follows.
<?xml version="1.0"?>
<instances>
<!-- This instance maintains connections to an Oracle database. -->
<instance id="oracle" socket="/tmp/oracle.socket" dbase="oracle">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
<!-- This instance maintains connections to an SAP database. -->
<instance id="sap" socket="/tmp/sap.socket" dbase="sap">
<connections>
<connection string="sybase=/opt/sap;lang=en_US;server=SAPSERVER;user=sapuser;password=sappassword;db=sapdb;"/>
</connections>
</instance>
<!-- This instance sends one set of users to the Oracle database and
all other users to the sap database. -->
<instance id="router" dbase="router">
<auths>
<auth module="sqlrclient_userlist">
<user user="oracleuser1" password="oraclepassword"/>
<user user="oracleuser2" password="oraclepassword"/>
<user user="oracleuser3" password="oraclepassword"/>
<user user="oracleuser4" password="oraclepassword"/>
<user user="sapuser1" password="sappassword"/>
<user user="sapuser2" password="sappassword"/>
<user user="sapuser3" password="sappassword"/>
<user user="sapuser4" password="sappassword"/>
</auth>
</auths>
<routers>
<router module="userlist" connectionid="oracle">
<user user="oracleuser1"/>
<user user="oracleuser2"/>
<user user="oracleuser3"/>
<user user="oracleuser4"/>
</router>
<router module="userlist" connectionid="sap">
<user user="*"/>
</router>
</routers>
<connections>
<connection connectionid="oracle" string="socket=/tmp/oracle.socket;user=scott;password=tiger"/>
<connection connectionid="sap" string="socket=/tmp/sap.socket;user=sapuser;password=sappassword"/>
</connections>
</instance>
</instances>
In this example, 3 SQL Relay instances are defined:
- one to maintain connections to an Oracle database
- one to maintain connections to a SAP database
- one to route queries to the other two instances
In this configuration, queries made by "oracle users" are routed to the connectionid "oracle", and all other queries are routed to the connectionid "sap".
The string attribute in each connection tag provides the parameters necessary to connect to the other instances. Valid parameters include:
- host - the host name or IP address of the SQL Relay instance
- port - the port of the SQL Relay instance
- socket - the socket of the SQL Relay instance, if it is running locally
- user - the user to use when connecting to the SQL Relay instance as
- password - the password to use when connecting to the SQL Relay instance
- fetchatonce - the number of rows to fetch at a time (defaults to 10, 0 means fetch the entire result set)
clientiplist
The clientiplist module routes queries by matching the client that ran the query against a list of IP addresses.

An example configuration follows.
<?xml version="1.0"?>
<instances>
<!-- This instance maintains connections to an Oracle database. -->
<instance id="oracle" socket="/tmp/oracle.socket" dbase="oracle">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
<!-- This instance maintains connections to an SAP database. -->
<instance id="sap" socket="/tmp/sap.socket" dbase="sap">
<connections>
<connection string="sybase=/opt/sap;lang=en_US;server=SAPSERVER;user=sapuser;password=sappassword;db=sapdb;"/>
</connections>
</instance>
<!-- This instance sends one set of users to the Oracle database and
all other users to the sap database. -->
<instance id="router" dbase="router">
<auths>
<auth module="sqlrclient_userlist">
<user user="routeruser" password="routerpassword"/>
</auth>
</auths>
<routers>
<router module="clientiplist" connectionid="master">
<client ip="192.168.*.0-50"/>
</router>
<router module="clientiplist" connectionid="slave">
<client ip="*"/>
</router>
</routers>
<connections>
<connection connectionid="oracle" string="socket=/tmp/oracle.socket;user=scott;password=tiger"/>
<connection connectionid="sap" string="socket=/tmp/sap.socket;user=sapuser;password=sappassword"/>
</connections>
</instance>
</instances>
In this example, 3 SQL Relay instances are defined:
- one to maintain connections to an Oracle database
- one to maintain connections to a SAP database
- one to route queries to the other two instances
In this configuration, queries made by users originating at IP addresses 192.168.*.0-50 are routed to the connectionid "oracle", and queries made by users originating at all other IP addresses are routed to the connectionid "sap".
Each octet of the ip attribute may be specfied as a number, a dash-separated range of numbers, or a * meaning "all possible values".
The string attribute in each connection tag provides the parameters necessary to connect to the other instances. Valid parameters include:
- host - the host name or IP address of the SQL Relay instance
- port - the port of the SQL Relay instance
- socket - the socket of the SQL Relay instance, if it is running locally
- user - the user to use when connecting to the SQL Relay instance as
- password - the password to use when connecting to the SQL Relay instance
- fetchatonce - the number of rows to fetch at a time (defaults to 10, 0 means fetch the entire result set)
clientinfolist
The clientinfolist module routes queries by matching the "client info" sent by the client against a list of regular expressions. The client info can be set using the setClientInfo() method/function provided by the native SQL Relay client API. When using PHP PDO, it can be set using the PDO_SQLRELAY_ATTR_CLIENT_INFO attribute. The client info cannot currently be set when using the ODBC, Perl DBI, PythonDB, or ADO.NET drivers.
An example configuration follows.
<?xml version="1.0"?>
<instances>
<!-- This instance maintains connections to an Oracle database. -->
<instance id="oracle" socket="/tmp/oracle.socket" dbase="oracle">
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
<!-- This instance maintains connections to an SAP database. -->
<instance id="sap" socket="/tmp/sap.socket" dbase="sap">
<connections>
<connection string="sybase=/opt/sap;lang=en_US;server=SAPSERVER;user=sapuser;password=sappassword;db=sapdb;"/>
</connections>
</instance>
<!-- This instance sends one set of users to the Oracle database and
all other users to the sap database. -->
<instance id="router" dbase="router">
<auths>
<auth module="sqlrclient_userlist">
<user user="routeruser" password="routerpassword"/>
</auth>
</auths>
<routers>
<router module="clientinfolist" connectionid="master">
<clientinfo pattern=".*oracle.*"/>
<clientinfo pattern=".*orcl.*"/>
</router>
<router module="clientinfolist" connectionid="slave">
<clientinfo pattern="*"/>
</router>
</routers>
<connections>
<connection connectionid="oracle" string="socket=/tmp/oracle.socket;user=scott;password=tiger"/>
<connection connectionid="sap" string="socket=/tmp/sap.socket;user=sapuser;password=sappassword"/>
</connections>
</instance>
</instances>
In this example, 3 SQL Relay instances are defined:
- one to maintain connections to an Oracle database
- one to maintain connections to a SAP database
- one to route queries to the other two instances
In this configuration, queries made by users who send client info which contains the string "oracle" or "ora1" to the connectionid "oracle", and queries made by users sending any other client info the connectionid "sap".
The string attribute in each connection tag provides the parameters necessary to connect to the other instances. Valid parameters include:
- host - the host name or IP address of the SQL Relay instance
- port - the port of the SQL Relay instance
- socket - the socket of the SQL Relay instance, if it is running locally
- user - the user to use when connecting to the SQL Relay instance as
- password - the password to use when connecting to the SQL Relay instance
- fetchatonce - the number of rows to fetch at a time (defaults to 10, 0 means fetch the entire result set)
usedatabase
The usedatabase module enables you to access databases across multiple database instances via the same SQL Relay front-end with "use database" queries.
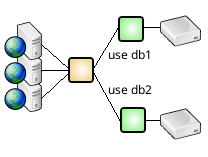
For example, lets say you have two database instances:
A MySQL/MariaDB instance that hosts 3 databases:
- mydb1
- mydb2
- mydb3
...and a PostgreSQL instance that hosts 2 databases:
- pg1
- pg2
If you configure an instance of SQL Relay to access the MySQL/MariaDB instance, then a SQL Relay client can run queries like "use mydb1" or "use mydb2" to select the database.
Similarly, if you configure an instance of SQL Relay to access the PostgreSQL instance, then a SQL Relay client can run queries like "use pbdb1" or "use pbdb2" to select the database.
The usedatabase module enables a client connected to a single instance of SQL Relay to select the database across both instances. For example, "use mydb1" would set the current database to the mydb1 database hosted by the MySQL/MariaDB instance, and "use pgdb2" would set the current database to the pgdb2 database hosted by the PostgreSQL instance.
An example configuration follows.
<?xml version="1.0"?>
<instances>
<!-- This instance maintains connections to a MySQL database -->
<instance id="mysqldb" dbase="mysql">
<listeners>
<listener port="" socket="/tmp/mysqldb.socket"/>
</listeners>
<connections>
<connection string="user=mysqldbuser;password=mysqldbpassword;host=mysqldb;db=mysqldb;"/>
</connections>
</instance>
<!-- This instance maintains connections to a PostgreSQL database -->
<instance id="postgresqldb" dbase="postgresql">
<listeners>
<listener port="" socket="/tmp/postgresqldb.socket"/>
</listeners>
<connections>
<connection string="user=postgresqldbuser;password=postgresqldbpassword;host=postgresqldb;db=postgresqldb;"/>
</connections>
</instance>
<!-- This instance sends queries to databases hosted by the mysql
instance and postgresql instance based on "use ..." queries. -->
<instance id="router" dbase="router">
<auths>
<auth module="sqlrclient_userlist">
<user user="routeruser" password="routerpassword"/>
</auth>
</auths>
<routers>
<router module="usedatabase"/>
</routers>
<connections>
<connection connectionid="mysqldb" string="socket=/tmp/mysqldb.socket;user=mysqldbuser;password=mysqldbpassword"/>
<connection connectionid="postgresqldb" string="socket=/tmp/postgresqldb.socket;user=postgresqldbuser;password=postgresqldbpassword"/>
</connections>
</instance>
</instances>
In this example, 3 SQL Relay instances are defined:
- one to maintain connections to an MySQL/MariaDB instance
- one to maintain connections to a PostgreSQL database
- one to route queries to the other two instances
The string attribute in each connection tag provides the parameters necessary to connect to the other instances. Valid parameters include:
- host - the host name or IP address of the SQL Relay instance
- port - the port of the SQL Relay instance
- socket - the socket of the SQL Relay instance, if it is running locally
- user - the user to use when connecting to the SQL Relay instance as
- password - the password to use when connecting to the SQL Relay instance
- fetchatonce - the number of rows to fetch at a time (defaults to 10, 0 means fetch the entire result set)
When the router instance starts, it gets the list of databases available from each of the other two instances, and routes to them accordingly.
A sample sqlrsh session follows:
sqlrsh -host localhost -user routeruser -password routerpassword
sqlrsh - Version 1.1.0
Connected to: localhost:9000 as routeruser
type help; for help.
0> use mydb1;
0> currentdb;
mydb1
0> select * from exampletable;
col1
==========================
this table is in db mydb1
Rows Returned : 1
Fields Returned : 1
Elapsed Time : 0.001512 sec
0> use mydb2;
0> currentdb;
mydb2
0> select * from exampletable;
col1
==========================
this table is in db mydb2
Rows Returned : 1
Fields Returned : 1
Elapsed Time : 0.001512 sec
0> use pgdb1;
0> currentdb;
pgdb1
0> select * from exampletable;
col1
==========================
this table is in db pgdb1
Rows Returned : 1
Fields Returned : 1
Elapsed Time : 0.001344 sec
0>
But... What if two different instances host databases with the same name? For example, what if your MySQL/MariaDB instance hosts a database named db2, and your PostgreSQL instance also hosts a database named db2?
To resolve situations like this, the usedatabase module enables you to map a database to an alias. In this example, the db2 database hosted by MySQL/MariaDB is mapped to mydb2, and the db2 database hosted by PostgreSQL is mapped to pgdb2.
<?xml version="1.0"?>
<instances>
... MySQL/PostgreSQL instance details omitted ...
<instance id="router" dbase="router">
<auths>
<auth module="sqlrclient_userlist">
<user user="routeruser" password="routerpassword"/>
</auth>
</auths>
<routers>
<router module="usedatabase">
<map connectionid="mysqldb" db="db2" alias="mydb2"/>
<map connectionid="postgresqldb" db="db3" alias="pgdb3"/>
</router>
</routers>
<connections>
<connection connectionid="mysqldb" string="socket=/tmp/mysqldb.socket;user=mysqldbuser;password=mysqldbpassword"/>
<connection connectionid="postgresqldb" string="socket=/tmp/postgresqldb.socket;user=postgresqldbuser;password=postgresqldbpassword"/>
</connections>
</instance>
</instances>
To access the db2 database hosted by MySQL/MariaDB, the user would run:
use mydb2
To access the db2 database hosted by PostgreSQL, the user would run:
use pgdb2
Attempts to "use db2" would fail.
Quirks and Limitations
Query Normalization
To make pattern matching easier, SQL Relay "normalizes" the query before matching it against the pattern. The original query is run against the database but when matched against the pattern, whitespace is compresssed and the entire query (except for quoted strings) is converted to lower-case.
When matching query operators, you must use lower-cased versions of them such as "select", "insert", "and", "or", etc. When matching table names, you must use a lower-cased version of the table-name.
Perl Compatible Regular Expressions
SQL Relay is built upon the Rudiments library. Rudiments can be built with or without support for libpcre which provides support for Perl Compatible Regular Expressions. PCRE's are more powerful than standard posix regular expressions and have many more operators.
As such, if you copy a configuration file from a machine where Rudiments was compiled with PCRE support to a machine where Rudiments wasn't compiled with PCRE support, then it's possible that your patterns may not work on the new machine.
To make matters worse, sufficiently old versions of the posix regular expression functions had fewer operators than modern versions. So, even if Rudiments isn't using PCRE's, it's not impossible that after copying a configuration file from a fairly modern OS to an antique, the patterns won't work on the antique machine either.
The examples above ought to work with PCRE's and all versions of posix regular expressions.
Selects Not Showing Changes
In the scenario above where DML/DDL is sent to the master database and selects are distributed over slaves, an unintuitive thing can happen.
If you begin a transaction and do several inserts, updates and deletes, you'll find that if you do a select, you will not see your changes. This is because in a master-slave configuration, changes to the database are not pushed out to the slaves until the changes have been committed. Since your selects are being run against the slaves, you must first commit before your changes will be visible.
Stored Procedures
It's possible to use stored procedures with SQL Relay's query routing feature. However, since stored procedures are run on the database, SQL Relay can't route the individual queries run inside the stored procedure. So, the stored procedure and all queries run inside of it will be run against whichever database it was routed to.
Parallel Transactions
Router modules like userlist, clientiplist, and clientinfolist route entire sessions to one database or another. Router modules like regex route individual queries. Behind the scenes, modules which route individual queries maintain parallel transactions on each of the databases that it is routing queries to, which present the following issues.
Integrity Violations
When the client issues a begin, commit or rollback, the router issues a begin, commit or rollback to each of the databases. Similarly, if the client turns auto-commit on or off, the router turns auto-commit on or off on each of the databases.
There are scenarios where a commit, rollback or auto-commit on/off command could succeed on some of the databases and fail on others. Some databases have a 2-phase commit feature to handle these scenarios. With 2-phase commit, you can roll back a commit until you do second commit. Many databases don't support 2-phase commit though. At present, SQL Relay doesn't currently support 2-phase commit for any database. So, currently, to handle this situation, SQL Relay returns an error, disables the instance doing the query routing, and raises an integrity_violation event. If a notification is configured to notify a DBA when an integrity_violation is raised, then the DBA will receive an email about the problem. Unfortunately, there is no standard way to solve the problem. The DBA must determine the cause, resolve it manually, and restart SQL Relay.
Commits and Rollbacks
Since queries may be routed to different kinds of databases, the router has to employ some tricks to maintain parallel transactions on dissimilar databases. Some databases run in auto-commit mode by default and must be issued a "begin" query to start a transaction. Other databases implicitly start a new transaction when a client logs in and after each commit or rollback. If any of the databases being routed to require a "begin" query to start a transaction, then the ones that don't are put in auto-commit mode when the client logs in and after each commit or rollback and are taken out of auto-commit mode when the client sends a begin query. If none of the databases being routed to require a "begin" query to start a transaction, then the databases are not put in auto-commit mode when the client logs in or after each commit or rollback. Rather, transactions are implicitly started by the database. For example, if your client application is using a router which routes queries over both PostgreSQL and Oracle databases, then since PostgreSQL requires "begin" queries, you must use a "begin" query to start a transaction, even if your app only intends to send queries which would be run against Oracle. Conversely, if your client application is using a router which only routes queries over a set of Oracle databases, then you do not have to use "begin" queries.
Custom Queries
Custom queries enable SQL Relay to return result sets for non-SQL queries.
Custom queries are implemented by loadable modules. The queries section of the configuration file indicates which modules to load and what parameters to use when executing them.
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <queries> <query module="sqlrcmdcstat"/> <query module="sqlrcmdgstat"/> </queries> ... </instance> ... </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
All query modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All query modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Custom query modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
At startup, the SQL Relay server creates instances of the specified query modules and initializes them. When a query is run, the server passes the query to each module, in the order that they were specified in the config file. Each module may evaluate the query and decide whether to respond or not. If none of the query modules respond, then the query is passed along to the database.
Currently, the following query modules are available in the standard SQL Relay distribution:
- sqlrcmdcstat
- sqlrcmdgstat
Custom modules may also be developed. For more information, please contact dev@firstworks.com.
sqlrcmdcstat
The sqlrcmdcstat module returns statistics about the sqlr-connection processes currently running for this instance of SQL Relay when the query "sqlrcmd cstat" is run.
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <queries> <query module="sqlrcmdcstat"/> </queries> ... </instance> ... </instances>
An example session follows:
sqlrsh - Version 1.7.0 Connected to: localhost:9000 as test type help; for help. 0> sqlrcmd cstat; INDEX MINE PROCESSID CONNECT STATE STATE_TIME CLIENT_ADDR CLIENT_INFO SQL_TEXT ===================================================================================================== 0 * 24464 1 RETURN_RESULT_SET 0.00 UNIX sqlrcmd cstat 1 24465 0 ANNOUNCE_AVAILABILITY 0.01 2 24466 0 WAIT_SEMAPHORE 4.42 3 24467 0 WAIT_SEMAPHORE 4.35 4 24468 0 WAIT_SEMAPHORE 4.34
In this example:
- the query "sqlrcmd cstat" has been run
- five sqlr-connection processes are running for this SQL Relay instance
- one sqlr-connection process is busy returning the result set of that command
- another sqlr-connection process is announcing that it is available to accept a client connection
- three other sqlr-connection processes are idle and waiting
The columns of the result set are as follows:
- INDEX - just a row index
- MINE - contains a * if this sqlr-connection is running the "sqlrcmd cstat" command and null otherwise
- PROCESSID - the OS process id of the sqlr-connection process
- CONNECT - the total number of times a client has connected to this process since it was last started
- STATE - one of the following...
- NOT_AVAILABLE - the current state is not available
- INIT - the process is initializing
- WAIT_FOR_AVAIL_DB - the process is waiting for the back-end database to become available
- WAIT_CLIENT - the process is waiting for a client to connect
- SESSION_START - the client session is in the process of starting
- GET_COMMAND - the process is waiting for the client to send it a command
- PROCESS_SQL - a query has been run and the process is waiting for the result set
- PROCESS_SQLCMD - a sqlcmd has been run and the process is building the result set
- RETURN_RESULT_SET - a query or sqlcmd has been run and the process is returning the result set
- END_SESSION - the client session is in the process of ending
- ANNOUNCE_AVAILABILITY - the process is announcing that it is ready to accept a client
- WAIT_SEMAPHORE - the process is idle and waiting for the opportunity to announce that it is ready
- STATE_TIME - the number of seconds that the process has been in the current state
- CLIENT_ADDR - the IP address of the client, or "UNIX" if the client is connecte via a unix socket
- CLIENT_INFO - an identifying "client info" string that some SQL Relay API's allow the client to set
- SQL_TEXT - the query or command that is currently running
sqlrcmdgstat
The sqlrcmdgstat module returns global statistics about this instance of SQL Relay when the query "sqlrcmd gstat" is run.
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <queries> <query module="sqlrcmdgstat"/> </queries> ... </instance> ... </instances>
An example session follows:
sqlrsh - Version 1.7.0 Connected to: localhost:9000 as test type help; for help. 0> sqlrcmd gstat; KEY VALUE =========================================== start 2019/10/27 23:06:16 uptime 930 now 2019/10/27 23:21:46 access_count 8 query_total 43 qpm 2 qpm_1 4 qpm_5 1 qpm_15 2 select_1 0 select_5 0 select_15 0 insert_1 0 insert_5 0 insert_15 0 update_1 0 update_5 0 update_15 0 delete_1 0 delete_5 0 delete_15 0 etc_1 4 etc_5 1 etc_15 2 sqlrcmd_1 0 sqlrcmd_5 0 sqlrcmd_15 0 max_listener 1000 max_listener_error 0 busy_listener 1 peak_listener 1 connection 5 session 1 peak_session 1 peak_session_1min 1 peak_session_1min_time 2019/10/27 23:21:46 sqlr_version 1.7.0 rudiments_version 1.2.1 module_compiled Oct 24 2019 22:20:05 Rows Returned : 39 Fields Returned : 78 Elapsed Time : 0.018508 sec
The result set is a set of key-value pairs, as follows:
- start - the date/time that the instance was started
- uptime - the number of seconds that the instance has been running
- now - the current date/time
- access_count - the number of times a client has connected to the instance
- query_total - the total number of queries that have been run, intance-wide
- qpm - queries-per-minute, averaged over total instance uptime
- qpm_1 - queries-per-minute, for the previous minute
- qpm_5 - queries-per-minute, averaged over the previous 5 minutes
- qpm_15 - queries-per-minute, averaged over the previous 15 minutes
- select_1 - selects-per-minute, averaged over total instance uptime
- select_5 - selects-per-minute, averaged over the previous 5 minutes
- seelct_15 - selects-per-minute, averaged over the previous 15 minutes
- insert_1 - inserts-per-minute, averaged over the total instance uptime
- insert_5 - inserts-per-minute, averaged over the previous 5 minutes
- insert_15 - inserts-per-minute, averaged over the previous 15 minutes
- update_1 - updates-per-minute, averaged over the total instance uptime
- update_5 - updates-per-minute, averaged over the previous 5 minutes
- update_15 - updates-per-minute, averaged over the previous 15 minutes
- delete_1 - deletes-per-minute, averaged over the total instance uptime
- delete_5 - deletes-per-minute, averaged over the previous 5 minutes
- delete_15 - deletes-per-minute, averaged over the previous 15 minutes
- etc_1 - other queries-per-minute, averaged over the total instance uptime
- etc_5 - other queries-per-minute, averaged over the previous 5 minutes
- etc_15 - other queries-per-minute, averaged over the previous 15 minutes
- sqlrcmd_1 - sqlrcmds-per-minute, averaged over the total instance uptime
- sqlrcmd_5 - sqlrcmds-per-minute, averaged over the previous 5 minutes
- sqlrcmd_15 - sqlrcmds-per-minute, averaged over the previous 15 minutes
- max_listener - value of the maxlisteners attribute of the instance tag for this instance (configured or default)
- max_listener_error - the number of times that the maximum number of sqlr-listener threads were running and another client attempted to connect since the instance was started
- busy_listener - the current number of sqlr-listener threads that are busy waiting for an available sqlr-connection to hand off a client to since the instance was started
- peak_listener - the peak number of sqlr-listener threads that were running at the same time since the instance was started
- connection - number of sqlr-connection processes currently running
- session - number of currently active client sessions
- peak_session - peak number of client sessions since the instance was started
- peak_session_1min - peak number of client sessions in the previous minute
- peak_session_1min_time - the time that the peak_session_1min value was calculated
- sqlr_version - the version number of the SQL Relay server
- rudiments_version - the version number of the Rudiments library that the SQL Relay server is using
- module_compiled - the date/time that the SQL Relay server was compiled
Triggers
Triggers enable SQL Relay to execute arbitrary code either before, or after a query is run. They are similar to a database trigger, but they run inside of SQL Relay, rather than inside of the database. As such, they are not limited to databaes operations. They can run queries, make library or system calls, run shell commands, and anything else that an os-level application can do.
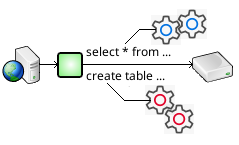
Triggers are implemented by loadable modules. The triggers section of the configuration file indicates which modules to load and what parameters to use when executing them.
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> <triggers> <trigger module="replay" when="after"> <condition error="1213" scope="transaction"/> <condition error="1205" scope="query"/> </trigger> </triggers> ... </instance> ... </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
All trigger modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All trigger modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
All trigger modules also have a when attribute which can be set to "before", "after", or "both", indicating whether to run the trigger before the query is executed, after the query has been executed, or both.
Trigger modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
At startup, the SQL Relay server creates instances of the specified trigger modules and initializes them. When a query is run, the server passes the query to each module, in the order that they were specified in the config file. Each module may evaluate the query and decide whether to run something or not.
Currently, the following trigger modules are available in the standard SQL Relay distribution:
- replay
- splitmultiinsert
- upsert
Custom modules may also be developed. For more information, please contact dev@firstworks.com.
replay
The replay module enables replay of the previous query, or of the entire transaction, when given conditions occur.
This enables automatic recovery in the event of a deadlock and/or lock wait timeout. It's possible that the module could be used for other purposes, but it's targeted for this use.
An example configuration:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> <triggers> <trigger module="replay" when="after"> <condition error="1213" scope="transaction"/> <condition error="1205" scope="query"/> </trigger> </triggers> ... </instance> ... </instances>
In this example...
The trigger is configured to run after the query has been executed. This is the only valid configuration for the replay trigger. If when="before" or when="both" is set then the trigger will be ignored.
If an error code 1213 occurs (a MySQL deadlock), then the entire transaction is replayed. If an error code 1205 occurs (a MySQL lock wait timeout), then the previous query is replayed.
Note that the normalize translation is also configured. This helps the trigger parse and rewrite queries more accurately. See the section on Auto-Increment Columns below for details.
Deadlocks aren't completely preventable, but if you know which queries caused the deadlock, then you can usually modify them (or the app) to mitigate the problem. The replay module allows you to specify a file to log to and a query to run and log the output of, for each condition. For example:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> <triggers> <trigger module="replay" when="after"> <condition error="1213" scope="transaction"> <log file="/tmp/example-deadlocks.log"> <query> show engine innodb status </query> </log> </condition> <condition error="1205" scope="query"/> </trigger> </triggers> ... </instance> ... </instances>
In this example...
If an error code 1213 occurs (a MySQL deadlock), then the module logs various bits of information to the log, runs the query "show engine innodb status" and outputs the results of the query to /tmp/example-deadlocks.log as well. Then, the entire transaction is replayed and details about that are logged to the file too.
If an error code 1205 occurs (a MySQL lock wait timeout), then the previous query is replayed, but no logging occurs.
In this configuration, the module enables automatic recovery from deadlocks and lock wait timeouts, and the log allows a developer to go back later, examine the queries that caused the deadlocks, and modify them (or the app) to mitigate the problem.
In addition to the module and when attributes, the trigger tag also supports the following attributes:
- includeselects
- If set to "no" (the default) - select queries are not logged or replayed
- If set to "yes" - select queries are logged and replayed
- Use care when disabling this, as the query log will be larger and replay operations can take much longer.
- maxretries
- It's possible to encounter another replay condition while replaying a query or transaction. If this happens, the module retries. This attribute limits the total number of retries. If it is exceeded, then whatever error occurred on the last retry is returned to the application.
The condition tag supports the following attributes:
- error
- if numeric: the condition is true if the error code matches
- if string: the condition is true if the error string contains the string
- scope
- transaction - replay the entire transaction if this condition occurs
- transaction - replay the previous query if this condition occurs
The log tag supports the following attributes:
- file
- the name of the file to log information to, including the output of the query specified in the query tag
- each log entry consists of a divider, timestamp, and result set
The query tag contains the query to be run
Sample (partial) log entries follow:
=============================================================================== 05/15/2019 15:59:40 EDT Type : InnoDB Name : Status : ===================================== 2019-05-15 15:59:40 7f2dcb118b00 INNODB MONITOR OUTPUT ===================================== Per second averages calculated from the last 9 seconds ----------------- BACKGROUND THREAD ----------------- srv_master_thread loops: 2625 srv_active, 0 srv_shutdown, 100871 srv_idle srv_master_thread log flush and writes: 103455 ... more lines ... Spin rounds per wait: 1.97 mutex, 5.00 RW-shared, 3.26 RW-excl ------------------------ LATEST DETECTED DEADLOCK ------------------------ 2019-05-15 15:59:40 7f2dcce8bb00 *** (1) TRANSACTION: TRANSACTION 1449294, ACTIVE 8 sec inserting mysql tables in use 1, locked 1 LOCK WAIT 38 lock struct(s), heap size 6544, 34 row lock(s), undo log entries 22 MySQL thread id 2400, OS thread handle 0x7f2dcb118b00, query id 339194 localhost testuser update ------------------------ LATEST DETECTED DEADLOCK ------------------------ 2019-05-15 15:59:40 7f2dcce8bb00 *** (1) TRANSACTION: TRANSACTION 1449294, ACTIVE 8 sec inserting mysql tables in use 1, locked 1 LOCK WAIT 38 lock struct(s), heap size 6544, 34 row lock(s), undo log entries 22 MySQL thread id 2400, OS thread handle 0x7f2dcb118b00, query id 339194 localhost testuser update insert into testtable (col1,col2,col3) values (null,0,2013183) *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 9786 page no 6352 n bits 696 index `col1` of table `testdb`.`testtable` trx table locks 13 total table locks 6 trx id 1449294 lock_mode X locks gap before rec insert intention waiting lock hold time 1 wait time before grant 0 *** (2) TRANSACTION: TRANSACTION 1449304, ACTIVE 7 sec fetching rows mysql tables in use 25, locked 25 18296 lock struct(s), heap size 2143784, 1437389 row lock(s) MySQL thread id 2361, OS thread handle 0x7f2dcce8bb00, query id 334173 localhost testuser Copying to tmp table on disk update testtable1,testtable2,testtable3 ... some long where clause ... some long set clause ... *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 9786 page no 6352 n bits 592 index `col1` of table `testdb`.`testtable` trx table locks 4 total table locks 6 trx id 1449304 lock mode S lock hold time 7 wait time before grant 0 *** (2) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 9786 page no 6327 n bits 368 index `GEN_CLUST_INDEX` of table `testdb`.`testtable` trx table locks 4 total table locks 6 trx id 1449304 lock mode S waiting lock hold time 0 wait time before grant 0 *** WE ROLL BACK TRANSACTION (1) ------------ TRANSACTIONS ------------ ... more lines ... =============================================================================== 05/15/2019 17:21:33 EDT Type : InnoDB Name : Status : ... more lines ...
From this log entry, we can see that insert and update queries encountered a gap-locking deadlock.
Currently, each condition tag may contain only one log tag, and each log tag may contain only one query tag. This restriction may be relaxed in a future release.
If the log file doesn't already exist, the it is created with rw-r--r-- permissions, and will be owned by the user/group that SQL Relay is running as. There aren't, currently, attributes to control permissions or ownership.
Considerations
There are some considerations that are important to take into account when using the replay module.
Deadlock Response
MySQL/MariaDB respond to a deadlock at the transaction level. When a deadlock occurs, they roll back all of the queries in the current transaction, and all of these queries must be reexecuted in order to recover. So, when using the replay module with MySQL/MariaDB and databases which respond similarly, use scope="transaction" in your conditions.
Oracle responds to a deadlock at the query level. When a deadlock occurs, it rolls back the query that deadlocked, and only that query must be reexecuted in order to recover. So, when using the replay module with Oracle and databases which respond similarly, use scope="query" in your conditions.
The replay module has been used extensively with MySQL/MariaDB, but not with other databases. It should work, but there might be unforseen issues. For example, the scope="transaction" behavior is modeled after the specific way that MySQL/MariaDB respond to a deadlock. When a deadlock occurs, they roll back all of the queries in the current transaction. However, you are still in the same transaction, it's just as if none of the queries had been run. As such, when replaying a transaction, the module just re-executes the queries that it logged - it doesn't execute a rollback, or begin a new transaction first. This may not be correct for all databases which handle deadlocks at the transaction level.
Memory Usage
Queries are, currently, just logged to memory. If your application runs large queries, and/or has long running transactions, then excess memory consumption could become an issue. The default behavior of not logging or replaying select queries helps, so use caution when disabling that option.
Retries
If, while replaying a query, or transaction, another replay condition is encountered, then the module will retry until the replay succeeds, or until maxretries is reached.
To avoid hammering the system, the module delays between retries. The delay is initially 10 milliseconds. This doubles with each retry until the delay reaches 1 second. Then that doubles until it reaches 10 seconds. From then on, the delay between retries is 10 seconds. This algorithm isn't currently configurable. It also isn't backed by any particular science. It just seems to work reasonably well.
Auto-Increment Columns
Auto-increment column values survive rollbacks. If an insert into a table with an auto-increment column generates the value 300, and that query is rolled back then the row will be removed. But, if the insert is run again, then it will generate the value 301 instead of 300.
To handle this, the replay module parses and rewrites insert queries to contain the last-insert-id's that they generated and logs the rewritten query instead of the original. Thus, when replayed, the query won't generate a value, but rather will re-use the value that it generated the first time.
There are some limitations to this.
- Multi-row inserts aren't directly supported if they generate auto-increment column values. These are impossible to support directly, as post-insert, the last-insert-id only returns the very last value that was generated, and it's not possible to collect the others. If your application does multi-row inserts into tables with auto-increment columns, then try loading the splitmultiinsert module prior to the replay module to split your multi-row inserts into a set of individual insert queries, which can be replayed.
- Insert-Select queries (eg. insert into onetable select from anothertable) and Select-Into queries (eg. select * from onetable into anothertable) are similarly not supported.
If any of those are detected, then the query log is cleared and the module is disabled until the beginning of the next transaction. If a replay condition occurs, then the error is just returned as it would have been if the module were not in use.
The module also has to do a bit of work to determine whether the insert contains an auto-increment column, including query the database for the last-insert-id, and potentially column info. Column info is cached, but the cache isn't shared across sqlr-connection processes, and is (currently) cleared at the end of each transaction. So, the module should be used with caution in performance-sensitive applications.
splitmultiinsert
The splitmultiinsert module splits each multi-row insert query into a set of individual insert queries.
This is useful when using the replay module, if your application does multi-row inserts into tables with auto-increment columns. See replay - Auto-Increment Columns above for details. This module can, of course, be used without the replay module, but the typical use case is to use the two of them together.
An example configuration:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> <triggers> <trigger module="splitmultiinsert" when="before"/> <trigger module="replay" when="after"> <condition error="1213" scope="transaction"/> <condition error="1205" scope="query"/> </trigger> </triggers> ... </instance> ... </instances>
In this example...
The splitmultiinsert trigger is configured to run before the query has been executed. This is the only valid configuration for the splitmultiinsert trigger. If when="after" or when="both" is set then the trigger will be ignored.
The replay trigger is also configured. In this configuration, the splitmultiinsert trigger supports the replay trigger by splitting multi-row inserts into a set of single-row inserts, for which it is possible to get the last-insert-id of each, if necessary.
Note that the normalize translation is also configured. This helps the splitmultiinsert and replay triggers parse and rewrite queries more accurately.
In this configuration, if a students table exists like:
create table students ( id int primary key auto_increment, firstname varchar2(128) not null, lastname varchar2(128) not null, major varchar2(128) )
...and the following multi-row insert was performed:
insert into
students (firstname,lastname,major)
values
('Richard','Muse','Mechanical Engineering'),
('David','Muse','Computer Science')
...then it would be split into the following two individual inserts:
insert into students (firstname,lastname,major) values ('Richard','Muse','Mechanical Engineering')
insert into students (firstname,lastname,major) values ('David','Muse','Computer Science')
The replay module would then be able to fetch the last-insert-id for each, and rewrite them, for replay, as:
insert into students (id,firstname,lastname,major) values (1,'Richard','Muse','Mechanical Engineering') insert into students (id,firstname,lastname,major) values (2,'David','Muse','Computer Science')
Considerations
The splitmultiinsert trigger imposes a performance penalty. Not only is there work involved in splitting the original query, but also, a set of individual inserts runs more slowly than a single multi-row insert.
The splitmultiinsert trigger also, currently, struggles with bind variables that are split across rows in the multi-insert query.
For example, consider a multi-row insert like the following:
insert into students (firstname,lastname,major) values (:1,:2,:3),(:4,:2,:3)
With the following bind variables:
1 - "David" 2 - "Muse" 3 - "Computer Science" 4 - "Richard"
Variables 2 and 3 apply to both rows, but variable 1 only applies to the first row and variable 4 only applies to the second row.
This query would be split into:
insert into students (firstname,lastname,major) values (:1,:2,:3) insert into students (firstname,lastname,major) values (:4,:2,:3)
But, currently, all 4 bind variables would be bound when executing both queries. This causes problems for most databases, as most databases refuse to execute queries with superfluous bind variables.
This will be remedied in the future, but is currently a shortcoming of this module.
upsert
The upsert module enables an insert query to be transparently interpreted as an update query, if the insert failed.
Both the set of errors that trigger the upsert, as well as the set of tables that can be upserted into are configurable.
An example configuration:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> <triggers> <trigger module="upsert" when="after"> <errors> <error string="ORA-00001"/> </errors> <tables> <table name="students"> <column name="FIRSTNAME"/> <column name="LASTNAME"/> </table> </tables> </trigger> </triggers> ... </instance> ... </instances>
In this example...
The trigger is configured to run after the query has been executed. This is the only valid configuration for the upsert trigger. If when="before" or when="both" is set then the trigger will be ignored.
If an insert into the table students results in an error string containing "ORA-00001" (an Oracle unique constraint violated), then the insert that generated the error will be converted to an update.
The where clause of the update will only contain columns FIRSTNAME and LASTNAME.
The trigger will also attempt to identify primary key and autoincrement columns and exclude them from the table update.
For example, if the students table exists like:
create table students ( id int primary key, firstname varchar2(128) not null, lastname varchar2(128) not null, major varchar2(128), year int, gpa number(2,1), unique (firstname,lastname) )
And two inserts are run like:
insert into students values (student_ids.nextval,'David','Muse','Mechanical Engineering',1,4.0); insert into students values (student_ids.nextval,'David','Muse','Computer Science',2,3.2);
Then the first insert will succeed, but the second will fail because the values of 'David' and 'Muse' for the firstname and lastname columns violate the unique constraint.
In this case, the second insert will throw an ORA-00001 error, and the trigger will be converted to the following update:
update students set firstname='David', lastname='Muse', major='Computer Science', year=2, gpa=3.2 where firstname='David' and lastname='Muse'
Note that the primary key is omitted from the set clause of the update, and that the where clause only contains the firstname and lastname columns.
Note also that, in the configuration, the columns are uppercased: FIRSTNAME and LASTNAME. This is because, in this example, we're using an Oracle database and Oracle column names are uppercased by default. For other databases, you should use lowercased column names.
Also note that, in the configuration, the normalize translation is included. This helps the trigger parse and rewrite queries more accurately.
Other configuration options are also available.
You can specify the error by number instead of by string:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <translations> <translation module="normalize"/> </translations> <triggers> <trigger module="upsert" when="after"> <errors> <error number="1"/> </errors> <tables> <table name="students"> <column name="FIRSTNAME"/> <column name="LASTNAME"/> </table> </tables> </trigger> </triggers> ... </instance> ... </instances>
If, for some reason, the trigger is unable to identify the primary key of the table, you can manually specify the primary key:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> <triggers> <trigger module="upsert" when="after"> <errors> <error string="ORA-00001"/> </errors> <tables> <table name="students"> <primaarykey name="ID"/> <column name="FIRSTNAME"/> <column name="LASTNAME"/> </table> </tables> </trigger> </triggers> ... </instance> ... </instances>
You can also specify multiple tables:
<?xml version="1.0"?> <instances> ... <instance id="example" ... > ... <querytranslations> <querytranslation module="normalize"/> </querytranslations> <triggers> <trigger module="upsert" when="after"> <errors> <error string="ORA-00001"/> </errors> <tables> <table name="students"> <column name="FIRSTNAME"/> <column name="LASTNAME"/> </table> <table name="professors"> <column name="FIRSTNAME"/> <column name="LASTNAME"/> </table> <table name="courses"> <column name="NUMBER"/> <column name="NAME"/> </table> </tables> </trigger> </triggers> ... </instance> ... </instances>
In the example configuration above, inserts into any of the students, processors, or courses tables, which fail with ORA-00001, will be converted to updates.
There are some considerations that need to be taken into account when using the upsert trigger.
- Currently, only single-row inserts are supported. Multi-row inserts, select-into, and insert-select queries will not be converted to update queries, and will just fail.
- If you don't specify any columns in the table tag, then the where clause of the generated update will be empty, and the update query will fail.
- If the insert doesn't contain values for the columns specified in the table tag, then the conversion to update will fail.
Logging
Logging enables the SQL Relay server programs to log various bits of information as they run.
Logging is implemented by loadable modules. The loggers section of the configuration file indicates which modules to load and what parameters to use when executing them.
<?xml version="1.0"?> <instances> <instance ...> ... <loggers> <logger module="debug" stdout="yes"/> </loggers> ... </instance> </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
Different modules may have different parameters. In this example, stdout="yes" tells the module to log debug info to standard output.
All logger modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All logger modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Logger modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
At startup, the SQL Relay server processes create instances of the specified logger modules and initialize them. As events occur, the server passes the event, log level, and optionally, a string of information about the event to each module, in the order that they were specified in the config file. If a module is listening for that event, at that log level, then it logs information about the event to a log file.
Currently, the following logger modules are available in the standard SQL Relay distribution:
- debug
- sql
- slowqueries
- stalecursors
Custom modules may also be developed. For more information, please contact dev@firstworks.com.
debug
The debug module enables logging of information about the internal operation of the SQL Relay server.
<?xml version="1.0"?> <instances> <instance ...> ... <loggers> <logger module="debug" stdout="yes"/> </loggers> ... </instance> </instances>
This module takes four attributes: stdout, stderr, file, and perms.
If stdout is set to "yes" then the module will log to standard output.
If stderr is set to "yes" then the module will log to standard error.
If file is set to "yes" (or not set to "no" and neither of stdout nor stderr are set to "yes") then the module will log to files in the "debug directory", usually /usr/local/firstworks/var/log/sqlrelay/debug, /usr/local/firstworks/var/sqlrelay/debug, or /var/log/sqlrelay/debug. It creates files named sqlr-listener."pid" and sqlr-connection."pid" where "pid" is replaced with the process id of the process that is being logged. As new processes are forked, new files are created with debug information about those processes.
The perms attribute may be set to any ls -l style permissions string, and will set the permissions of the debug files, if file is also set to "yes". The default is "rw-------" which translates to read/write for owner only.
The stdout, stderr, and file parameters are not mutually exclusive. Any combination of them may be set to "yes".
Note, that including a logger tag for the debug module doesn't enable debugging, by itself. Rather, it just defines the destination of any debug that is otherwise enabled. To enable debugging of a particular module or component, you must include debug="yes" attributes in other tags.
For example...
To enable debugging of all components of SQL Relay, include debug="yes" in the instance tag.
<?xml version="1.0"?> <instances> <instance ... debug="yes"> ... </instance> </instances>
To enable debugging of the sqlr-listener process, include debug="yes" in the listeners tag.
<?xml version="1.0"?> <instances> <instance ...> <listeners debug="yes"> ... </listeners> ... </instance> </instances>
To enable debugging of a front-end protocol, include debug="yes" in an individual listener tag.
<?xml version="1.0"?> <instances> <instance> <listeners> <listener ... debug="yes"/> ... </listeners> ... </instance> </instances>
To enable debugging of the sqlr-connection process, include debug="yes" in the connections tag.
<?xml version="1.0"?> <instances> <instance ...> ... <connections debug="yes"> ... </connections> </instance> </instances>
To enable debugging of an individual module, include debug="yes" in the tag for an individual module.
<?xml version="1.0"?> <instances> <instance ...> ... <querytranslations> <querytranslation module="normalize" ... debug="yes"/> </querytranslations> ... </instance> </instances>
And so on.
Actually, it's not even explicitly necessary to include a logger tag for the debug module if you just want to log debug to standard output. If a debug="yes" attribute is included in any valid location in the config file, then the debug module will be implicitly loaded, with the stdout="yes" option enabled.
Debugging to standard output is handy in a highly constrained dev or QA environemnt. But, if you need to debug any environment with multiple, simultaneous client sessions, debugging to standard output can become confusing, as debug from multiple processes will all be sent to standard output, interleved. If you need to debug such an environment, it is recommended to use the file="yes" option, and debug each process to a separate file:
<?xml version="1.0"?> <instances> <instance ...> ... <loggers> <logger module="debug" file="yes"/> </loggers> ... </instance> </instances>
sql
The sql module logs all queries to log files in the "log directory", usually /usr/local/firstworks/var/log/sqlrelay, /usr/local/firstworks/var/sqlrelay/log, or /var/log/sqlrelay. It creates files named sqlr-connection-"id"-querylog."pid" for each sqlr-connection process where "id" is replaced with the id of the instance from the configuration file and "pid" is replaced with the process id.
<?xml version="1.0"?> <instances> <instance ...> ... <loggers> <logger module="sql" sync="yes" queryevent="received" logpidchange="yes"/> </loggers> ... </instance> </instances>
This module takes four attributes: sync, queryevent, logerrors, and logpidchange.
If sync is set to "yes" then data will be written to the log synchronously, that is, data will be written to the log immediately and completely after each query has been executed. This degrades performance, sometimes significantly, but makes it easier to monitor the log. If sync is set to "no" (the default) then data will be written to the log asynchronously, that is, data may not be written to the log immediately or completely after each query has been executed. This improves performance, sometimes significantly, but makes it it more difficult to monitor the log, and may require an sqlr-stop to be executed for the final bit of data to be written to the log.
The queryevent parameter may be set to received, prepared, or executed. The behavior of each is summarized as follows:
- received - Each query is logged as soon as it is received by SQL Relay. All queries are logged. No errors can be logged.
- prepared - Each query is logged after it has been prepared. Queries filtered out by a filter module are not logged. If an error occurs during preparation, then the error may be logged.
- executed - The default. Each query is logged after it has been executed. Queries filtered out by a filter module or that failed to prepare are not logged. Queries may be logged multiple times if they are prepared once and executed over and over. If an error occurs during exceution, then the error may be logged.
- logerrors - In addition to the query, log prepare/execute errors, if they occur.
- logpidchange - Log process id changes.
The general format is:
select 1 from dual; select 2 from dual; select 3 from dual;
Errors are logged like:
-- ERROR: ORA-00942: table or view does not exist
Process ID changes are logged like:
-- pid changed to 12423
slowqueries
The slowqueries module logs queries that take longer to run than a specified threshold to log files in the "log directory", usually /usr/local/firstworks/var/log/sqlrelay, /usr/local/firstworks/var/sqlrelay/log, or /var/log/sqlrelay. It creates files named sqlr-connection-"id"-querylog."pid" for each sqlr-connection process where "id" is replaced with the id of the instance from the configuration file and "pid" is replaced with the process id.
<?xml version="1.0"?> <instances> <instance ...> ... <loggers> <logger module="slowqueries" sec="10" usec="0"/> </loggers> ... </instance> </instances>
This module takes three attributes: sec, usec, and sync.
Queries that take longer than sec seconds and usec microseconds will be logged. Both attributes default to 0 and omitting them causes all queries to be logged.
If sync is set to "yes" then data will be written to the log synchronously, that is, data will be written to the log immediately and completely after each query has been executed. This degrades performance, sometimes significantly, but makes it easier to monitor the log. If sync is set to "no" (the default) then data will be written to the log asynchronously, that is, data may not be written to the log immediately or completely after each query has been executed. This improves performance, sometimes significantly, but makes it it more difficult to monitor the log, and may require an sqlr-stop to be executed for the final bit of data to be written to the log.
The general format is:
Mon 2014 Apr 6 15:58:17 : select 1 from dual time: 0.000001
Sample log: sqlr-connection-oracletest-querylog.2899
stalecursors
It is not uncommon for a long-running application to open a cursor, and then never close it again. So-called "cursor leaks" eventually lead to No server-side cursors were available to process the query (or similar) errors, and the root cause can be difficult to track down, especially if a lower-level database abstraction layer does the opening and closing of the cursors.
The stalecursors module logs active cursors, enabling an administrator to see if any cursors have been open for a long time, and if so, what the last query the cursor ran was.
The module works by opening a connection to another instance of SQL Relay (the "log instance"), where it creates a table named "stalecursors" and logs to that table.
In the following example, the "stalecursors" instance (the log instance) provides access to a database where the stale cursors can be logged, and the "example" instance (the app instance) logs cursor activity there.
<?xml version="1.0"?>
<instances>
<instance id="stalecursors" socket="/tmp/stalecursors.socket" dbase="mysql" connections="5" maxconnections="10" translatebindvariables="yes">
<connections>
<connection string="user=testuser;password=testpassword;db=testdb;host=mysql;foundrows=yes"/>
</connections>
</instance>
<instance id="example" dbase="mysql">
<loggers>
<logger module="stalecursors" socket="/tmp/stalecursors.socket" user="stalecursorsuser" password="stalecursorspassword"/>
</loggers>
<connections>
<connection string="user=mysqluser;password=mysqlpassword;db=mysqldb;host=mysqlhost"/>
</connections>
</instance>
</instances>
In the log instance, note the following:
- It is configured to listen on a unix socket, but not configured to listen on a port. This is because the app instance is running on the same machine. This is not a requirement though. The log instance could be configured to listen on a port as well, and serve app instances running on other machines.
- translatebindvariable="yes" is set. The queries that the module generates to insert, update, and delete from the stalecursors table use oracle-style (colon-delimited) bind variables. If the log database is something other than oracle, then the log instance must translate the bind variables.
- connections="5" and maxconnections="10" are set. By default, SQL Relay opens 5 connections to the database. The app instance uses this default configuration. If the log instance also only opens 5 connections, then all 5 will be consumed by the app instance, and it won't be possible to access and examine the log from a client program. So, we'll allow the log instance to scale up accordingly.
The module takes 5 attributes: host, port, socket, user, and password. These attributes are used to access the other instance of SQL Relay that will be used for logging.
When a cursor is opened, the module adds a new row to the log. Each time a query is executed, the row is updated. When the cursor is closed, the module removes the row.
If the cursor is never closed, then the row is never removed, even if the application exits. The row will also persist across sqlr-starts and sqlr-stops of the app instance and log instances. As such, it will eventually be necessary to manually clear to the table, or at least manually delete rows from it, analogous to deleting log files.
To view currently active (and possibly stale) cursors, you would access the log instance like:
sqlrsh -socket /tmp/stalecursors.socket -user stalecursorsuser -password stalecursorspassword
And then view the log like:
select * from stalecursors
A typical result set would be something like:
instance connection_id connection_pid cursor_id most_recent_query most_recent_query_timestamp =================================================================================================== example example-0 27155 0 select * from bigtable 2019-10-24 20:34:06 example example-0 27158 0 select * from mytable 2019-10-24 20:34:26 example example-0 27162 0 select * from yourtable 2019-10-24 20:34:41 example example-0 27166 0 select * from thistable 2019-10-24 20:34:53 example example-0 27168 0 select * from thattable 2019-10-24 20:35:03
Multiple app instances may log to the same log instance. To view cursor activity for a particular instance, just filter on the "instance" column.
select * from stalecursors where instance='example'
Note that each connection of an app instance will consume 1 connection of the log instance, so be sure to configure the log instance to start enough connections to the database. Eg. if you have 2 app instances, each configured with connections="5", then the log instance should be configured with connections="10" and maxconnections set to something larger than 10 to allow for clients to connect and examine the logs.
Notifications
Notifications allow the SQL Relay server programs to notify recipients when a specified set of events occur.

Notifications are implemented by loadable modules. The notifications section of the configuration file indicates which notification modules to load and what parameters to use when executing them.
<?xml version="1.0"?> <instances> <instance ...> ... <notifications> <notification module="events"> <events> <event event="db_error"/> <event event="db_warning"/> <event event="filter_violation"/> </events> <recipients> <recipient address="dev@firstworks.com"/> </recipients> </notification> </notifications> ... </instance> </instances>
The module attribute specifies which module to load.
Module configurations may have attributes and/or nested tags. How these are interpreted is module-specific.
All notification modules have an enabled attribute, allowing the module to be temporarily disabled. If enabled="no" is configured, then the module is disabled. If set to any other value, or omitted, then the module is enabled.
All notification modules have a debug attribute. If debug="yes" is configured then debugging information is written to the destination of the debug logger module (if one is defined, see the debug logger module), or otherwise, to standard output. If debug="no" is configured, or if the debug attribute is omitted, then no debugging information is written.
Notification modules can be "stacked". Multiple different modules may be loaded and multiple instances of the same type of module, with different configurations, may also be loaded.
<?xml version="1.0"?> <instances> <instance ...> ... <notifications> <notification module="events"> <events> <event event="db_error"/> <event event="db_warning"/> <event event="filter_violation"/> </events> <recipients> <recipient address="dev@firstworks.com"/> </recipients> </notification> <notification module="events"> <events> <event event="integrity_violation"/> </events> <recipients> <recipient address="dba@firstworks.com"/> </recipients> </notification> </notifications> ... </instance> </instances>
At startup, the SQL Relay server processes create instances of the specified notification modules and initializes them. As events occur, the server passes the event and, optionally, a string of information about the event to each module, in the order that they were specified in the config file. If a module is listening for that event, then it sends a notification to the specified recpients.
Currently, the following notification module is available in the standard SQL Relay distribution:
- events
Custom modules may also be developed. For more information, please contact dev@firstworks.com.
events
The events module listens for a specified set of events and notifies recipients when a one occurs.
An example configuration follows.
<?xml version="1.0"?> <instances> <instance ...> ... <notifications> <notification module="events"> <events> <event event="db_error"/> <event event="db_warning"/> <event event="filter_violation"/> </events> <recipients> <recipient address="dev@firstworks.com"/> </recipients> </notification> </notifications> ... </instance> </instances>
In this example, the module sends notifications to dev@firstworks.com when one of the db_error, db_warning, or filter_violation events occurs.
The events tag defines the set of events to listen for. Valid events are:
- client_connected - An SQL Relay client connected to the SQL Relay server.
- client_connection_refused - An SQL Relay client attempted to connect to the SQL Relay server but the server refused the connection, usually because authentication failed.
- client_disconnected - An SQL Relay client disconnected from the SQL Relay server.
- client_protocol_error - The SQL Relay server didn't understand something that the SQL Relay client sent to it.
- db_login - The SQL Relay server opened a connection to the database.
- db_logout - The SQL Relay server closed a connection to the database.
- db_error - A query generated an error.
- db_warning - A query generated a warning.
- query_executed - A query was executed.
- filter_violation - A query filter module prevented a query from being executed.
- internal_error - An internal error occurred.
- internal_warning - An internal warning occurred.
- debug_message - A debug message was generated.
- schedule_violation - A connection schedule module prevented a user from logging in to the SQL Relay server.
- integrity_violation - A query routing module is in use and a transaction control query (begin, commit, rollback, autocommit on, or autocommit off) succeeded on some of the back-ends but failed on others.
Any number of events may be specified. Each event must be specified in its own event tag. The event tag supports the following attributes:
- event - Required. The event to listen for.
- pattern - Optional. Only valid when event="query". A regular expression limiting the set of queries that the notification will be sent for. If set, then the notification will only be sent if the query matches the pattern. If omitted, then the notification will be sent for all queries.
Any number of recipients may also be specified. Each recipient must be specified in its own recipient tag. The recipient tag supports the following attributes:
- address - Required. The address to send the notification message to.
- subject - Optional. The subject of the notification message.
- template - Optional. The filename of the template to use for the notification message.
Currently, notifications may only be sent via email.
If the subject attribute is not provided, then SQL Relay uses a default subject of:
SQL Relay Notification: @event@
Where @event@ is replaced with the event that triggered the notification.
If the template attribute is not provided, then SQL Relay uses a default template of:
SQL Relay Notification: Event : @event@ Event Info : @eventinfo@ Date : @datetime@ Host Name : @hostname@ Instance : @instance@ Process Id : @pid@ Client Address : @clientaddr@ Client Info : @clientinfo@ User : @user@ Query : @query@
In both subject lines and template files, the following substitutions can be made:
- @event@ - The event that triggered the notification.
- @eventinfo@ - The text (if any) that accompanied the event.
- @datetime@ - The date/time that the event occurred.
- @hostname@ - The host name of the server hosting the SQL Relay instance that generated the event.
- @instance@ - The instance name of the SQL Relay instance that generated the event.
- @pid@ - The process id of the SQL Relay instance that generated the event.
- @clientaddr@ - The client address (if any) of the SQL Relay client that was connected when the event occurred.
- @clientinfo@ - The client info (if any) of the SQL Relay client that was connected when the event occurred.
- @user@ - The SQL Relay user (if any) that was logged in to the SQL Relay instance that generated the event.
- @query@ - The query (if any) that was running when the event occurred.
On linux/unix systems, the mail program is used to send notifications. Messages are sent using the following command:
mail -s subject address < message
Where subject is replaced with the subject, address is replaced with the recipient and messagee is replaced with the name of the temporary file that is used to store the message.
SQL Relay assumes that the mail program is installed, in the PATH of the user that SQL Relay runs as, and that mail delivery is configured on the host system.
On Windows systems the blat program is used to send notifications. Messages are sent using the following command:
blat message -to address -subject subject -q
Where subject is replaced with the subject, address is replaced with the recipient and message is replaced with the name of the temporary file that is used to store the message.
SQL Relay assumes that the blat program is installed, in the PATH of the user that SQL Relay runs as, and that blat has been configured. See http://www.blat.net to download and configure blat.
Session-Queries
SQL Relay can be configured to run a set of queries at the beginning and end of each client session.
By far the most common use for this feature is that some database parameter needs to be reconfigured but you don't have permission or bouncing the database is out of the question, or something like that. For example, lets say you are using an Oracle database, but your app requires dates to be formatted like MM/DD/YYYY instead of DD-MON-YYYY. Ideally you'd alter the nls_date_format in the instance but you can't, for some reason.
You can use SQL Relay's session queries to work around the problem.
In the following example, the date format is set to MM/DD/YYYY at the beginning of the session and then reset back to DD-MON-YYYY at the end.
<?xml version="1.0"?>
<instances>
<instance id="example">
<session>
<start>
<runquery>alter session set nls_date_format='MM/DD/YYYY'</runquery>
</start>
<end>
<runquery>alter session set nls_date_format='DD-MON-YYYY'</runquery>
</end>
</session>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
Actually, in this example, there's no need to set the date format back to DD-MON-YYYY but it's done here for illustrative purposes.
Alternative Configuration File Options
Configuration Directory
While any number of SQL Relay instances can be defined in a single configuration file, it might be more convenient to split configurations up into multiple files located in a configuration directory.
The default SQL Relay configuration directory depends on the platform and on how you installed SQL Relay.
- Unix and Linux
- Built from source - /usr/local/firstworks/etc/sqlrelay.conf.d (unless you specified a non-standard --prefix or --sysconfdir during the build)
- RPM package - /etc/sqlrelay.conf.d
- FreeBSD package - /usr/local/etc/sqlrelay.conf.d
- NetBSD package - /usr/pkg/etc/sqlrelay.conf.d
- OpenBSD package - /usr/local/etc/sqlrelay.conf.d
- Windows
- Built from source - C:\Program Files\Firstworks\etc\sqlrelay.conf.d
- Windows Installer package - C:\Program Files\Firstworks\etc\sqlrelay.conf.d (unless you specified a non-standard installation folder)
Additional configuration files may be created under this directory. These files must follow the same format as the main configuration file.
For example, if you wanted to split up oracle, sap and db2 configurations into 3 separate files, you could create:
sqlrelay.conf.d/oracle.conf
<?xml version="1.0"?>
<instances>
<instance id="oracleexample">
<listeners>
<listener port="9000"/>
</listeners>
<connections>
<connection string="user=scott;password=tiger;oracle_sid=ora1"/>
</connections>
</instance>
</instances>
sqlrelay.conf.d/sap.conf
<?xml version="1.0"?>
<instances>
<instance id="sapexample" dbase="sap">
<listeners>
<listener port="9001"/>
</listeners>
<connections>
<connection string="sybase=/opt/sap;lang=en_US;server=SAPSERVER;user=sapuser;password=sappassword;db=sapdb"/>
</connections>
</instance>
</instances>
sqlrelay.conf.d/db2.conf
<?xml version="1.0"?>
<instances>
<instance id="db2example" dbase="db2">
<listeners>
<listener port="9002"/>
</listeners>
<connections>
<connection string="db=exampledb;user=db2inst1;password=db2inst1pass;lang=C;connecttimeout=0"/>
</connections>
</instance>
</instances>
Specifying Configuration Files
It is also possible to specify a particular configuration file or directory by passing the sqlr-start program a -config option.
For example:
sqlr-start -id oracleexample -config /home/myuser/sqlrelay.conf sqlr-start -id oracleexample -config file:///home/myuser/sqlrelay.conf sqlr-start -id oracleexample -config dir:///home/myuser/sqlrelay.conf.d
( NOTE: When installed from packages, SQL Relay may have to be started and stopped as root.)
(the file:// prefix is optional when specifying a file, but the dir:// prefix must be included when specifying a directory)
The -config option may also be used to specify a comma-separated list of files or directories.
For example:
sqlr-start -id oracleexample -config /home/myuser/sqlrelay-1.conf,/home/myuser/sqlrelay-2.conf sqlr-start -id oracleexample -config /home/myuser/sqlrelay-1.conf,/home/myuser/sqlrelay-2.conf,dir:///home/myuser/sqlrelay.conf.d sqlr-start -id oracleexample -config /home/myuser/sqlrelay-1.conf,/home/myuser/sqlrelay-2.conf,dir:///home/myuser/sqlrelay-1.conf.d,dir:///home/myuser/sqlrelay-2.conf.d
( NOTE: When installed from packages, SQL Relay may have to be started and stopped as root.)
Files and directories are processed in the order that they are specified.
Remote Configuration Files
In addition to local configuration files, the -config option may also be used to specify configuration files located on a remote host, accessible via http.
Actually, if the Rudiments library upon which SQL Relay depends was compiled with support for libcurl, then configuration files may also be remotely accessible over other protocols supported by libcurl, such as https, ftp, scp, sftp, smb, etc.
For example:
sqlr-start -id oracleexample -config http://configserver.mydomain.com/sqlrconfig/sqlrelay.conf sqlr-start -id oracleexample -config http://myuser:mypassword@configserver.mydomain.com/sqlrconfig/sqlrelay.conf sqlr-start -id oracleexample -config http://[/usr/local/firstworks/etc/sqlruserpwd.txt]@configserver.mydomain.com/sqlrconfig/sqlrelay.conf sqlr-start -id oracleexample -config https://configserver.mydomain.com/sqlrconfig/sqlrelay.conf sqlr-start -id oracleexample -config https://myuser:mypassword@configserver.mydomain.com/sqlrconfig/sqlrelay.conf sqlr-start -id oracleexample -config https://[/usr/local/firstworks/etc/sqlruserpwd.txt]@configserver.mydomain.com/sqlrconfig/sqlrelay.conf sqlr-start -id oracleexample -config scp://myuser:mypassword@configserver.mydomain.com/usr/local/firstworks/etc/sqlrelay.conf sqlr-start -id oracleexample -config scp://[/usr/local/firstworks/etc/sqlruserpwd.txt]@configserver.mydomain.com/usr/local/firstworks/etc/sqlrelay.conf
( NOTE: When installed from packages, SQL Relay may have to be started and stopped as root.)
( NOTE: The https and scp examples only work if Rudiments was compiled with support for libcurl.)
In some of the examples above, a user and password are given in the url, separated by a colon, prior to the @ sign. In other examples, in place of a literal user and password, a user-password file is specified in square brackets. If a user-password file is used, then the file should contain a single line, consisting of colon-separated user and password.
For example:
myuser:mypassword
Password protection is recommended for remotely accessible configuration files as they may contain users and passwords for accessing the database and SQL Relay itself.
Using user-password files is recommended over passing literal users and passwords. The files can be protected with file permissions, they prevent the user and password from being stored in the script that starts SQL Relay, and they prevent the user and password from being displayed in a process listing.
Link Files
So far, the example configuration files have all been XML files, containing configurations for instances of SQL Relay.
However, a configuration file can, alternatively, be a "link file", containing nothing but links to other configuration files.
For example:
# oracle configuration http://myuser:mypassword@configserver.mydomain.com/sqlrconfig/oracle.conf # sap/sybase configuration http://myuser:mypassword@configserver.mydomain.com/sqlrconfig/sap.conf # db2 configuration http://myuser:mypassword@configserver.mydomain.com/sqlrconfig/db2.conf
Lines starting with # are considered to be comments and blank lines are ignored, but every other line is interpreted as the location of a local configuration file, local configuration directory, or remote configuration file, as described in the previous sections.
Each of these files or directories are processed in the order that they are specified.
Link files can be used to centralize configuration. For example, if you have several SQL Relay servers, rather than distributing configuration files across the servers, you could create an identical sqlrelay.conf file on each of them like:
http://myuser:mypassword@configserver.mydomain.com/sqlrconfig/sqlrelay.conf
And then, on configserver.mydomain.com, host an sqlrelay.conf file like:
http://myuser:mypassword@configserver.mydomain.com/sqlrconfig/oracle.conf http://myuser:mypassword@configserver.mydomain.com/sqlrconfig/sap.conf http://myuser:mypassword@configserver.mydomain.com/sqlrconfig/db2.conf
The files oracle.conf, sap.conf, and db2.conf could then be hosted by and maintained on that server as well.
The links in these examples are all urls, but they could just as easily be links to local files and directories as well. It is important to note though, that SQL Relay interprets all local file and directory locations relative to the local machine. If a remotely hosted link file contains a reference to a local file or directory, then SQL Relay will look for that file on the local machine, not the remote machine.
Similarly, urls are resolved using the DNS configuration of the local machine as well, not the DNS configuration of the remote machine.
The urls in these examples all contain literal users and passwords. User-password files can also be used as described in the section Remote Configuration Files. However, the user-password file must exist at the specified location on the local machine.
As link files can be protected by file permissions, and the urls stored in them aren't exposed anywhere else, such as in a process listing, user-password files are not generally necessary when using link files.
There is no limit to the depth of links. A link file can reference another link file which references another, which references another, etc. Too great a depth could lead to slow startup times though, especially when using remote configration files. This is especially significant when using Dynamic Scaling, as the configuration must be loaded each time a new connection is spawned. Care should also be taken to avoid loops.
Advanced Configuration
The configuration file supports many more attributes and features than the ones described in this guide including tuning options. See the SQL Relay Configuration Reference and Tuning SQL Relay for more information.

